AWS Solutions Architect Associate - Everything You Need To Know
Passing the AWS Solutions Architect Associate exam is no mean feat and this blog post is a testament to that. Below you will find all of the information required to get you over the line in the exam. Don’t forget it is important to use more than one resource when studying for an exam as in depth as the SAA. For a video course I cannot recommend Adrian Cantrill’s Solutions Architect Course enough - it is probably the best value for money cloud course on the internet. In fact much of the post below is composed from my notes for that exact course.
KEY
BLUE - Important Words and Concepts
Purple - AWS Specific Services, Tools and Concepts
RED - Code Snippets (JSON, YAML etc.)
Cloud Basics
There are some cloud basics to keep in mind when designing cloud solutions. A good solution should adhere to the five principles below:
- On-Demand Self-Service - Provision and Terminate using a UI/CLI without human interaction
- Broad Network Access - Access services over any networks on any devices, using standard protocols and methods
- Resource Pooling - Cloud providers pool resources that can be used by many different tenants. Take advantage of this.
- Rapid Elasticity - Scale UP and DOWN automatically in response to system load.
- Measured Service - Usage is measured and you pay for what you consume.
Infrastructure solutions can only be cloud if they offer the 5 above principles.
These may seem like quite obvious cloud benefits, the point is that Cloud Solutions Architect is an architecting exam and so answers are geared towards solutions that best take advantage of benefits of the cloud.
Public vs Private vs Multi vs Hybrid
- Public Cloud - Using one public cloud (AWS, GCP, Azure)
- Private Cloud - Using on premises real cloud. Meaning using an on prem solution that offers the 5 above principles.
- Multi-Cloud - Using more than one public cloud
- Hybrid Cloud - Using public and private clouds in conjunction.
- Hybrid cloud is NOT public cloud + legacy on premises. The on prem solution has to be considered 'cloud' as well. (Offers at least the 5 above principles)
High Availability
- HA aims to ensure an agreed level of operational performance, usually uptime for a higher than normal period.
- HA doesn't aim to prevent failures entirely, it is a system designed to be up as much as possible. Often using automation to bring systems back into service as quickly as possible.
- It is about maximising a systems online time.
- Good High Availability is all about redundancy. If a server fails you can hot swap in a standby server. This way the downtime is only the time in which it takes to switch. Without this you would have to diagnose and fix the failure before the system could be available again.
Fault Tolerance
- Similar to HA but is different.
- Fault Tolerance is the property that enables a system to continue operating properly in the event of the failure of some of its components.
- If the system has faults then it should continue operating properly. FT means a system should carry on operating through a failure without bringing down the system.
- HA is just about maximising uptime, Fault Tolerance is about operating through failure.
Difference between Fault Tolerance and High Availability:
- You're in a Jeep driving through the desert, you get a flat tire. No worries you have a spare (redundancy) you stop the jeep and swap in your spare tire and then carry on driving. This is high availability, you didn't have to fix the existing tire as you had a spare to swap in which massively reduced the amount of time the Jeep wasn't running.
- Now you're in a plane and an engine fails. You can't just stop the plane or you fall out of the sky and everyone dies. Instead the other 3 engines are designed to pick up the slack, This is fault tolerance the plane (the system) is designed so that if one crucial element fails there are already redundancies running to prevent any downtime whatsoever.
- In High Availability you may have a main server and a back up server, in the event of a failure you switch to the back up server. There is minimal downtime in the switch but there is some and it can cause disruption to users eg. having to re log in.
- In Fault Tolerance both servers are connected to the system at all times and the system can run on either one or both simultaneously without negative effects. This way if a server fails there is no downtime during switch and no user disruption as the remaining server was always connected and part of the session.
- Fault Tolerance is a lot more expensive than High Availability and it is harder to design and implement.
Disaster Recovery
- A set of policies, tools and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster.
- Pre-plan the processes and documentation for what to do in the event of a disaster.
- DR is designed to keep the crucial and non replaceable parts of your system safe in the event of a disaster.
AWS Accounts
Different to the users using the account. Big projects and businesses typically use many AWS accounts.
At a high level an AWS account is a container for identities and resources
Every AWS account has a unique Account Root User with a unique email address.
The ARU has full control over that one specific AWS account and the resources inside it. The ARU cannot be restricted.
This is why you need to be very careful with the Account Root User.
Even though the ARU can't be restricted, you can create other identities inside the account that can be restricted.
These are created with Identity and Access Management (IAM).
Identities start out with no or limited access to the account and can be granted permissions as needed.
AWS accounts can contain the impact of admin errors, or exploits by bad actors. Use separate accounts for separate things.
Eg. a Development Account, Test Account and Prod Account. This way you can limit problems to specific accounts rather than letting them affect your entire business.
Multi Factor Authentication
Factors - different pieces of evidence which prove identity.
4 common factors:
- Knowledge - something you know, usernames and passwords
- Possession - Something you have eg. bank card, MFA Device
- Inherent - Something you are, fingerprint, face, voice.
- Location - A physical location, which network (corporate or Wifi)
More factors means more security and harder to fake.
A username and password are both things you know. So by themselves they are single factor as they only use the knowledge factor.
Billing Alerts
My billing dashboard - central location for managing costs.
Cost Explorer - extensive break down of costs
Good Initial Account Setup
- Add Multi Factor Auth for the root user (My security credentials)
- Tick all billing preferences boxes (Billing Dashboard)
- Add a Billing Alert for usage (cloudwatch - Make sure in N. Virginia region)
- Enable IAM User & Role Access to billing (my account)
- Add account contacts (myaccount -> alternate contacts)
- Create IAM identities for regular account use
IAM - Identity & Access Management
Best practice is to only use root user for initial account set up. Afterwards utilise IAM identities. This is because there is no way to restrict permissions on root user.
IAM Basics:
There are 3 types of IAM identity objects: Users, Groups and Roles
- Users - Identities which represent humans or applications that need access to your account.
- Groups - Just collections of related users. eg. Development Team, Finance, HR
- Role - Can be used by AWS Services or for granting external access to your account. Generally used when the number of things you want to grant access is uncertain. Eg. you want to grant all EC2 instances access but you wouldn't know exactly how many there will be.
IAM Policy: Allow or deny access to AWS services when attached to IAM Users, Groups or Roles. On their own they do nothing, they simply allow or deny access to services. Only when you attach them to an IAM Identity do they provide a function.
IAM has three main jobs:
- Identity provider (IDP) create identities such as Users and Roles
- Allows you to authenticate those identities. Generally with a username and password.
- Authorises access or denies access to AWS Services and tools
More on IAM:
- Provided at No Cost (with some exceptions)
- Global Service with Global Resilience it has one global database for your account.
- Only controls what its identities can do. Allows or Denies based on IAM policies.
- Allows you to use identity federation and MFA
IAM Access Keys:
Keys allow you to access AWS Services via means other than the AWS Management Console eg. AWS CLI
- An IAM User has 1 Username and 1 Password
- An IAM User can have two access keys - This is to allow users to rotate in new access keys and rotate out old ones
- Access keys can be created, deleted, made inactive or made active.
- Made up of an Access Key ID and a Secret Key - AWS will only show you the Secret Key once when created and never again after.
Setting up keys on AWS:
- Go to top right of AWS Management Console where log in drop down is -> my security credentials
- Click Create access key
- Note down both Access Key ID and Secret Key, AWS will only show you this Secret Key once. You can also download the keys in a CSV.
Install AWS CLI:
- Test installation by typing 'aws --version' in your standard command line.
- If installation successful it should print the version you are using.
- If not you may need to restart the machine.
Configure your AWS Keys on AWS CLI:
- aws configure --profile iam-username
- Enter AWS Access Key ID
- Enter Secret Access Key
- Enter Default Region eg. us-east-1
- Enter Default Output format. Can leave as None (just press enter) and will default to JSON
- Test set up with a command eg. aws s3 ls --profile iam-username # If you don't specify the --profile then it won't know where to look and won't work.
- Output will be empty string if you have no s3 buckets set up on account, or a list of s3 buckets if there are some set up. If setup was incorrect there will be an error message.

YAML - 'YAML Ain't Markup Language' BASICS
One of the languages used by CloudFormation (Infrastructure as Code)
A Language which is human readable and designed for data serialization. For defining data or configuration.
At a high level a YAML document is an unordered collection of Key:Value pairs.
Key:Value explained:
Say you have 3 dogs you can put their names in a key value pair:
dog1:Rover
dog2:Rex
dog3:Jeff
Note that these Keys and Values are all strings but YAML supports other types such as: Numbers, Floating Point (decimals), Boolean (true or false) and Null.
YAML also supports Lists:
mydogs: ["Rover", "Rex", "Jeff"] # This is inline formatting
These are comma separated elements enclosed within [square brackets]
You can format lists in another way (not inline):
mydogs:
- "Rover"
- 'Rex'
- Jeff
Notice how you can use double quotes, apostrophes or neither. All are valid syntax, enclosing in quotes or apostrophes can be more precise with typing (strings, numbers etc.)
Indentation matters in YAML in the mydogs list immediately above (not inline) Rover, Rex and Jeff are all indented the same amount so YAML knows these are all part of the same list.
This means you can nest lists in lists by using the same indentation.
YAML Dictionary:
mydogs:
- name: Rover
colour: [black, white]
- name: Rex
colour: "Mixed"
- name: Jeff
colour: "brown"
numoflegs: 3
In this case, mydogs is a list of dictionaries.
Notice how there are 7 lines but only 3 hyphens, well each hyphen denotes the start of a dictionary which is an unordered set of Key:Value pairs.
You can tell all 3 items in the list are part of the mydogs Key as there is only one level of indentation.
You can also have lists within dictionaries, notice in the Key:Value pair for Rover's Colour there is an inline list [black, white]
Using YAML Key:Value Pairs, Lists and Dictionaries allows you to build complex data structures in a way which is human readable. In this case just a simple database of a persons dogs.
YAML files can be read into an application or written out by an application and is commonly used for storage and passing of configuration (infrastructure as code).
JavaScript Object Notation (JSON) BASICS
JSON is an alternative format which is used in AWS. Where YAML is generally only used for CloudFormation, JSON is used for both CloudFormation and other things like IAM Policy Documents.
JSON is a lightweight data interchange format. It's easy for humans to read and write. It's easy for machines to parse and generate.
JSON doesn't really care about indentation as everything is enclosed in something. Due to this it can be a lot more forgiving than YAML around spacing and positioning.
A Few definitions to be aware of to get to grips with JSON:
An object is an unordered set of key:value pairs enclosed by {curly braces}
{"dog1": "Rover", "Colour": "White"} #This is the same as a dictionary in YAML
An array is an ordered collections of values separated by commas and enclosed in [square brackets]
["Rover", "Rex", "Jeff"] # This is the same as a list in YAML
Values in JSON can be Strings, Objects, Numbers, Arrays, Boolean or Null
Example of a simple JSON document:

Notice how the entire document is enclosed in {curly braces} this is because at a top level a JSON document is simply a JSON object.
In the above example there are 3 keys: cats, colors and numofeyes. Each value for these keys is an array (list).
JSON doesn't require indentation as it uses speech marks, curly braces and square brackets. However indentation will make it easier to read.
Networking Basics
OSI 7-Layer Model
The OSI Model is conceptual and not always how networking is implemented but it is a good foundation.
The term networking stack refers to this, the software the performs each of the below functions:
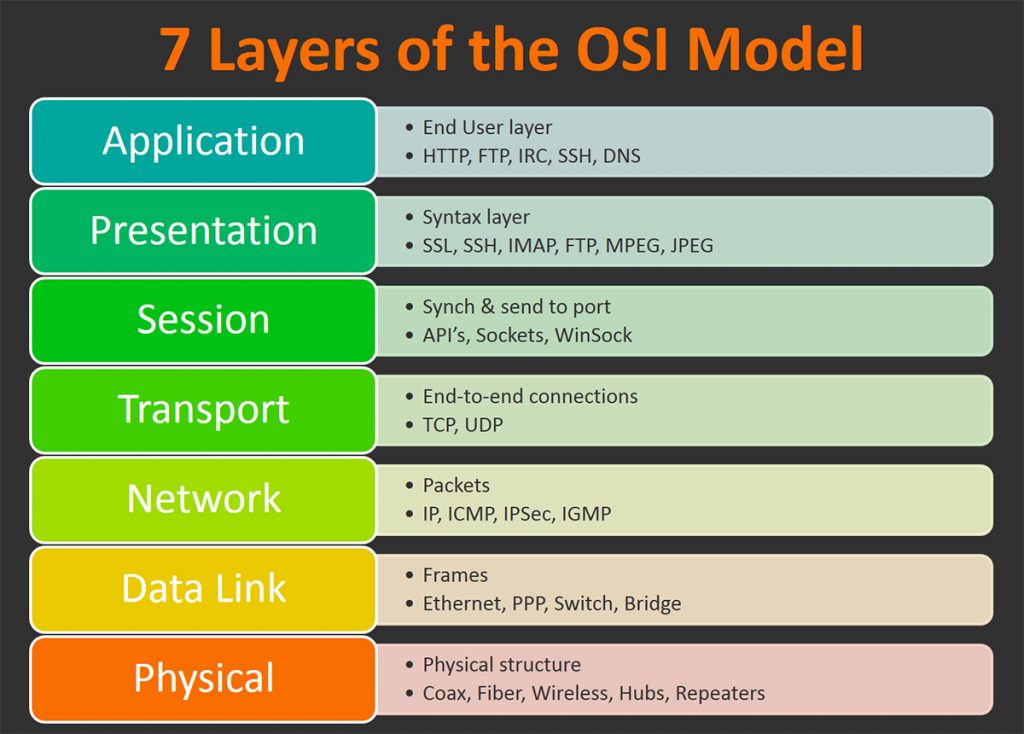
There are 2 groups in the OSI model:
- Physical, Data Link and Network comprise the Media Layers - Deals with how data is moved between Point A and Point B, whether locally or across the planet.
- Transport, Session, Presentation and Application comprise the Host Layers - How the data is chopped up and reassembled for transport and how it is formatted to be understandable by both ends of the network.
A layer one device just understands layer 1.
A layer three device has layer 1, 2 & 3 capability.
And so on...
Layer 1: Physical
Physical medium can be copper (electrical), fibre (light) or WIFI (RF).
Whatever medium is used it needs a way to carry unstructured information.
Layer 1 (Physical) specifications define the transmission and reception of RAW BIT STREAMS between a device and a shared physical medium (copper, fibre, WIFI). Defines things like voltage levels, timing, rates, distances, modulation and connectors.
For instance transmission of data between two hypothetical laptops can happen because both laptops network cards agree on the layer one specifications, this enables 0s and 1s to be transferred across the shared physical medium.
At layer one there is no individual device addresses. One laptop cannot specifically address traffic at another, it is a broadcast medium. Everything else on the network receives all data sent by one device, this is solved by layer 2.
If multiple devices transmit at once - a collision can occur. Layer 1 has no media access control and no collision detection.
Layer 2: Data Link
One of the most critical layers in the entire OSI model.
A layer 2 network can run on any type of layer 1 network (copper, fibre, WIFI etc.).
There are different layer 2 protocols and standards but one of the most common is Ethernet.
Layer 2 introduces MAC addresses, these are 48 bit addresses that are uniquely assigned to a specific piece of hardware. The MAC address on a network card should be globally unique.
Layer 2 introduces the concept of frames:

Layer 2 fundamentally encapsulates data in frames. Encapsulation is important to know as each layer of the OSI model performs some encapsulation of data as the data is passed down the layers.
A frame contains a preamble of 56 bits (prior to the mac addresses) this is to indicate the start of a frame.
Then you have the MAC header which is the destination MAC address, the source MAC address and finally the Ether Type which is the Layer 3 protocol being used to send the data (eg. TCP/IP)
Following on from the MAC header is the Payload, this is the actual data the frame will carry from source to destination. This data is typically provided by the Layer 3 protocol (as defined in the MAC header).
The layer 3 data is put into a layer 2 frame, this frame is sent across the physical medium by layer 1 to a different layer 2 destination. The payload data is then extracted and given back to layer 3 at the destination. It knows which Layer 3 protocol to hand the data off to at destination because it is defined in the frame by the Ether Type.
Finally at the end of the frame there is the CRC Checksum which is used to determine any errors in the frame. It allows the destination to check if there has been any corruption.
It is critical to understand that Layer 2 requires a Layer 1 network in order to function. Layer 2 sits on top of Layer 1. Layer 2 can prevent collisions and data corruption by ensuring that there is not currently data being transmitted by another device before it transmits its own data. In this way Layer 2 adds access control to the layer 1 physical medium.
Layer 2 gives us:
- Identifiable devices - frames can be uniquely addressed to other devices
- Media Access Control - Layer 2 controls access to Layer 1
- Collision prevention and detection
Layer 3: Network
Layer 3 gets data from one location to another.
Layer 3 is a solution that can move data between layer 2 networks, even if those layer 2 networks use different layer 2 protocols.
Internet Protocol (IP) is a layer 3 protocol which adds cross-network IP addressing and routing to move data between Local Area Networks without direct P2P links. So you can move data between two local networks across a continent without a direct link between the two. IP packets are moved step by step from source to destination via intermediate networks using routers. Routers are Layer 3 devices.
Packet Structure:
Where as with layer 2 frames the source and destination addresses are generally part of the same local network, the source and destination at layer 3 could be on different sides of the planet.
layer 3 Packets are placed in the payload part of a layer 2 frame.

Every packet has a Source IP Address generally the device address that generated the request. They also have a Destination IP Address where the packet is intended to go.
Additionally as in the diagram each packet has a protocol attached to it. These are Layer 4 protocols for instance TCP or UDP. This field means at the destination the device knows which layer 4 protocol to pass the data in the packet to.
Time-to-live defines the maximum number of hops the packet can take before being discarded, this ensures that if it can't be routed correctly to its destination it doesn't just bounce around forever.
Data contains the data being carried in the packet.
IP Addressing:
This will cover IPv4 but not IPv6 which is covered later on.
Example of an IP address: 133.33.3.7
This is known as Dotted-Decimal-Notation four numbers from 0-255 separated by dots.
All IP addresses are formed of two different parts:
- The first two numbers are the 'network part' - These numbers represent the network itself.
- The second two numbers are the 'host part' - These two numbers are used by devices on the network.
So 133.33 will represent someone's network
3.7 will then represent a device on that network (the devices address being 133.33.3.7)
If the network part of two IP addresses match, it means they're on the same IP network. If not they are on different networks.
An IP address is made up of four 8 bit numbers for 32 bits in total. Each 8 bit number then is sometimes referred to as an octet
IP addresses are either statically assigned by humans or they can be dynamically assigned by a protocol. On a network IP addresses need to be unique.
Subnet Masks:
These allow a device to determine if an IP address is local or remote. Is it on the same network or not.
They essentially specify to a device which part of an IP address represents the network and which part represents hosts on that network.
An in depth definition can be found here.
Route Tables & Routes:
Every router has an IP Route Table. When a packet is sent, the router reads the destination IP address and checks it against its table to see if there is a matching entry for where it can then send the packet on to.
The more specific the match the better, for instance if you want to find 64.216.12.33 then the router may have both 64.216.12.0/24 and 0.0.0.0/0 in its table, these would both match.
This is because the /24 essentially says the first 24 bits have been filled and this IP address represents a network comprising all 255 addresses possible: 64.216.12.(0-255).
So this matches because 64.216.12.33 is one of those 255 addresses. Specifically it is a device / server on the 64.216.12.0/24 network.
0.0.0.0/0 also matches 64.216.12.33 because 0.0.0.0/0 literally matches all IP addresses. In the same way /24 represents 255 addresses (24 bits filled in) /0 represents all IP addresses (no bits filled in). So from the Routers point of view 0.0.0.0/0 is a network of all IP addresses and so the IP address you are looking for would be part of this. However as there is a more specific option in 64.216.12.0/24 the router will choose to send the packet to the destination corresponding to 64.216.12.0/24 in its IP route table.
0.0.0.0/0 is often used as a default destination in a route table. If no other match can be found then this address will always match so the router sends the packet to whatever destination is specified by 0.0.0.0/0 presumably a more in depth IP Route Table.
Address Resolution Protocol (ARP):
Provides the MAC Address for a given IP address.
In order to put the Layer 3 data into a Layer 2 frame you're required to specify the Destination MAC Address in the frame.
So ARP runs between Layer 3 and Layer 2 in order to get the Layer 2 Mac Address from the Layer 3 IP Address.
Layer 4: Transport
Layer 4 Transport runs over the top of the network layer and provides most of the functionality to support the networking we use from day to day.
Layer 4 solves issues that can arise with just Layer 3 protocols:
- The Layer 3 IP protocol sends packets from one location to another but doesn't have a way to ensure they arrive in order or if they do arrive out of order how to piece the packets together into coherent data. Packets can arrive out of order because Layer 3 routing is 'per packet' so each packet can take a different route dependent on network conditions at the time.
- Additionally with only Layer 3 there is no way to know which packets have arrived at the destination and which haven't.
- IP also offers no way to separate the packets for individual applications, this means at a Layer 3 level you could only run one application at a time on the network.
- It also offers no flow control. If the source transmits faster than the destination can receive it can saturate the destination causing packet loss
Layer 4 brings two new protocols:
- TCP - Transmission Control Protocol - Slower / Reliable
- UDP - User Datagram Protocol - Faster / Less Reliable
Both of these run on top of IP and add different features dependent on which one is used. TCP/IP is commonly used and this just means TCP at Layer 4 running on top of IP at Layer 3.
TCP In Depth:
TCP introduces Segments which are just another container like packets and frames. Segments are contained in (encapsulated within) IP packets. The packets carry the segments from source to destination. Segments don't have source and destination IP addresses because they use the packets to do this instead.
Structure of a segment:
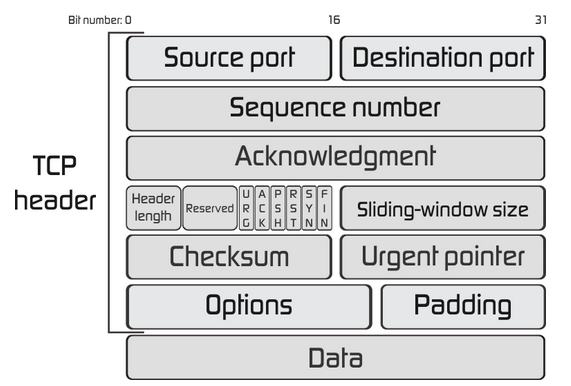
TCP segments add Source and Destination Ports. This gives the combined TCP/IP protocol the ability to have multiple data streams running at the same time between two devices.
The Source & Destination Ports and IP addresses together identify a single conversation (data stream) happening between two devices.
The Sequence Number is a way of uniquely identifying a particular segment in a data stream and is used to order data. So even if the packets turn up out of order they can be reordered correctly by the segment sequence number.
The Acknowledgement is the way that one side can indicate it has received up to and include a certain sequence number. Essentially how one side of the conversation can communicate which data packets might need resending in case they have been lost. This is what makes TCP more reliable than UDP it includes acknowledgements so the sender of data knows which packets have and haven't arrived. Check out this video which explains this concept and TCP/IP really well.
The Sliding Window Size solves the flow control problem. Defines the number of bytes indicated by the receiver that they are willing to receive between acknowledgements. This means that if this limit is reached the sender will stop sending data until they receive another acknowledgment, in this way the receiver is not overloaded (saturated) and data isn't lost.
TCP is a connection based protocol. A connection is established between two devices using a random port on a client and a known port on the server (eg. HTTPS 443). Once established the connection is bi-directional and it is considered reliable.
Important TCP Ports:
- tcp/80 - HTTP
- tcp/443 - HTTPS
- tcp/22 - SSH
- tcp/25 - SMTP (email)
- tcp/21 - Telnet
- tcp/3389 - Remote Desktop Protocol
- tcp/3306 - MySQL/MariaDB/Aurora
Network Address Translation (NAT):
NAT is designed to overcome IPv4 shortages.
It translates Private IPv4 addresses to Public addresses.
- Static NAT - 1 private device IP is assigned to a specific public address, useful when a particular private IP needs to have a consistent public IP. This is used by the Internet Gateway (IGW) in AWS.
- Dynamic NAT - 1 private device IP picks the 1st available public address from a pool. This public IP can be different the next time around. Multiple private devices can then share 1 public IP.
- Port Address Translation - Many private addresses to 1 public address. The method the NAT Gateway uses in AWS.
NAT also offers more security because it obscures the IP addresses of resources on a private network. This way outside actors can only know the IP address of the NAT device but not the addresses of the resources it routes to in the private network.
See this video for a good overall explanation of NAT.
IP Addressing
- IPv4 is still the most popular network layer protocol on the internet.
- IPv4 goes from 0.0.0.0 -> 255.255.255.255 = 4,294,967,296 addresses. ( not enough considering 8 billion population and lots of people have more than one device)
- All public IPv4 addressing is allocated. You have to be allocated these addresses.
- Part of the address space in IPv4 is private and can be used and reused freely within private networks.
There are 3 ranges of IPv4 addresses that can be used in private networks and can't be used as public addresses.
- The first private range is Class A: 10.0.0.0 - 10.255.255.255 this is just 1 network and it provides a total of 16.7 million addresses. This is generally used in cloud environment private networks and is usually chopped up into smaller subnets.
- The second private range is Class B: 172.16.0.0 - 172.31.255.255 this is a collection of 16 networks (16-31) each network contains 65,536 addresses.
- The third private range is Class C 192.168.0.0 - 192.168.255.255 this is a collection of 256 networks each containing 256 addresses. This is generally used in home and small office networks.
You can use these ranges however you like, but you should always aim to allocate non overlapping ranges to all of your networks.
IPv4 vs IPv6:
IPv4 has 4.2 billion addresses whereas IPv6 has 340 sextillion addresses. IPv6 has 4 quadrillion addresses per person alive today.
IP Subnetting
Classless inter domain routing (CIDR) lets us take a network of IP addresses and break them down into smaller subnets.
CIDR specifies the size of a subnet via slash notation:
- Slash notation uses prefixes tail -50f /var/log/legerity/fastpost/lol-uat/20220117165138_recoverdb.logeg. /8, /16, /24 and /32
- Lets say you are using a Class A private network. Without subnetting this runs from 10.0.0.0 - 10.255.255.255 or 16.7 million addresses.
- CIDR allows us to specify a small selection of this like 10.16.0.0/16 in this example the first 2 octets are taken leaving the remaining two (0.0) for the subnet (65,536 addresses).
- Essentially we have allocated the address space from 10.16.0.0 - 10.16.255.255 to our subnet via CIDR
- If we were to specify 10.0.0.0/8 this is the same as the entire Class A network, the first octet of the address is taken (10) leaving 0.0.0 - 255.255.255 (16.7 million addresses).
- The larger the prefix value (/16, /24 etc.) the smaller the network.
- You could actually have a /17 network this is basically half a /16 network. So 10.16.128.0/17 is half of 10.16.0.0/16 as the first 128 of the third octet in the /17 are already occupied so it only runs from 128.0 - 255.255.
- Similarly you could have /18 network this is half of a /17 network so 10.16.192.0/18. 192 is halfway between 128 and 255 so it is a /17 network cut in half. Four /18 networks are the size of one /16 network.
- /0 is the entire internet 0.0.0.0
Distributed Denial of Service (DDoS)
- Attacks designed to overload websites
- Uses large amounts of fake traffic to compete against legitimate connections
- Distributed - hard to block individual IPs/Ranges in an attempt to stop it
SSL and TLS
SSL - Secure Sockets Layer
TLS - Transport Layer Security
TLS is just a newer and more secure version of SSL.
They both provide privacy and data integrity between client and server.
TLS benefits:
- Ensures privacy by making communications between the client and server encrypted.
- Identity verification allows the client to verify the server and vice versa.
- Provides a reliable connection - protects against data alteration in transit.
Domain Name System (DNS) Basics
- DNS is a discovery service
- Translates machine into human and vice versa.
- For example humans use www.amazon.com to access Amazon but this needs to be translated into an IP address. DNS provides this service.
- DNS is a huge distributed and resilient database
- There are over 4billion IPv4 addresses and even more IPv6 and DNS has to be able to handle that scale.
DNS definitions:
- DNS Client - your laptop, phone, tablet, PC. The device that want's the information on a DNS server.
- Resolver - Software on your device, router or server which queries DNS on your behalf.
- DNS Zone - Part of the DNS database, every website URL has it's own Zone.
- Zonefile - The physical database for a zone.
- Nameserver - where zonefiles are located.
Your DNS Client asks the resolver to find the information for a given URL. The resolver queries DNS to find the correct Zone and Nameserver and then pulls the requisite information from the Nameserver eg. the IP address for which to send data.
AWS Fundamentals
AWS Public vs Private Services
All AWS services can be categorised into one of these two types.
When discussing public and private they relate to networking only. Whether a service is private or public is down to connectivity.
An AWS public service is one that can be connected to from anywhere with an unrestricted internet connection. For instance when you are accessing data stored in S3 you are connecting to it via the internet so S3 is a public service.
S3 sits in the public zone along with other AWS public services.
There is also a private zone in AWS. This by default does not allow any connections between the private zone and anywhere else. The private zone can be subdivided using Virtual Private Clouds or VPCs.
AWS Global Infrastructure
AWS Regions - Areas of the world with a full deployment of AWS infrastructure (compute, storage, DB, AI etc.). AWS is constantly adding regions, some countries have one region others have multiple regions. Regions are geographically spread so you can use them to design systems that are resilient to disasters.
AWS Edge Locations - Much smaller than regions but much more plentiful. Allows services to store data and resources as close to customers as possible. They don't offer the same breadth of services as Regions. Think more like Netflix needing to store its TV and Film data close to as many customers as possible to reduce latency.
Some services are region specific like EC2 so each needs its own individual deployment in each region. Others like IAM are global.
Regions have 3 main benefits:
- Geographic Separation - Isolated Fault Domain
- Geopolitical Separation - Different Governance - your data and infrastructure is governed by the rules of the government of that region.
- Location Control - Place infrastructure as close to customers as possible. Easily expand into new markets.
Regions can be referred to by their Region Code or Region Name.
For instance the region in Sydney is:
Region Code: ap-southeast-2
Region Name: Asia Pacific (Sydney)
If you had infrastructure in the Sydney region and a mirror of it in the London region then if Sydney failed it wouldn't affect your London infrastructure as it is isolated.
Availability Zones:
You will also want resiliency within regions, and AWS provides Availability Zones (AZ)for this. AZs are isolated "datacentres" within a region, as a Solutions Architect you can distribute your systems across AZs to build resilience and provide high availability.
You can place a private network across multiple Availability Zones with a Virtual Private Cloud (VPC).
Resilience Levels:
Globally Resilient - A service distributed across multiple regions, it would take the world to fail for the service to experience an outage. Examples of this are IAM and Route 53
Region Resilient - Services that operate in a single region with one set of data per region. They operate as separate services in each region and generally replicate data across multiple AZs within the region. If the region fails the service will fail.
AZ Resilient - Services run from a single AZ, if that AZ fails then the service will fail.
Virtual Private Cloud (VPC)
VPC is the service used to create private networks inside AWS that other private services will run from. It is also the service that connects your private networks with on-prem networks when you are building a hybrid solution. Additionally it can connect AWS with other cloud providers when using a multi cloud solution.
A VPC is a virtual network inside AWS.
A VPC is within 1 account and 1 region. They are regionally resilient as they operate across multiple AZs within one region.
By default a VPC is private and isolated unless you decide otherwise. Resources can communicate with other resources within the VPC itself.
There are two types of VPC in a region - The Default VPC and Custom VPCs. You can only have ONE Default VPC per region. You can have many Custom VPCs in a region.
As the name suggest Custom VPCs can be configured anyway you want and are 100% private by default. Unless configured otherwise there is no way for Custom VPCs to communicate outside of their own private network.
Default VPCs are initially created by AWS in a region and are very specifically configured making them more restrictive.
VPC Regional Resilience:
Within a region every VPC is allocated a range of IP Addresses, the VPC CIDR.
Everything inside that VPC uses the CIDR range of that VPC.
Custom VPCs can have multiple CIDR ranges, the Default VPC always has one range and it is always the same: 172.31.0.0/16
The way in which a VPC can provide resilience is that it is subdivided into subnets and each subnet is placed in a different Availability Zone.
The Default VPC is always configured in the same way - it has one subnet in every availability zone in its region. So if a region has 3 AZs the Default VPC will have 3 subnets, one in each with the CIDR block 172.31.0.0/16 split evenly across those 3 subnets.
VPCs IN AWS
In your AWS account you can view the Default VPC by typing VPC in the search bar. Then select "Your VPCs" you will then see one or more VPCs and one of them will be set as the Default VPC.
You can view the subnets set up for this VPC (one in each AZ) in the Subnets section under Your VPCs.
All regions on your account will have a Default VPC - when you have Your VPCs or Subnets open switch to a region you have never used before and you will still see a preconfigured Default VPC.
In the same section you will see along with the Default VPC a Network ACL and Security group are also pre-created. The can be see under the security tab in the sidebar. Additionally an Internet Gateway is pre-created.
You can delete a Default VPC:-- Your VPCs -> Select the Default VPC -> Then Delete it.
You can recreate a Default VPC if it has been deleted. Go to actions and Create Default VPC. You do not use the 'Create VPC' button for this as that is only for Custom VPCs.
Elastic Compute Cloud (EC2)
The default starting point for any compute requirement in AWS.
- EC2 is IAAS - Provides Virtual Machines known as instances
- Private service - Configured to launch into a single VPC subnet you have to allow public access (internet) as by default it is private.
- EC2 is only AZ resilient if the AZ fails the EC2 instance itself fails. This is because it is launched in one subnet and a subnet exists in one AZ.
- Different sizes and capabilities are available to choose from when configuring EC2 instances.
- Offers on demand billing - you only pay for what you consume.
- Two main types of storage - Local on Host Storage or Elastic Block Store (EBS)
EC2 instances have an attribute called a state. They can be in one of a few states, most commonly:
- Running
- Stopped
- Terminated
When an instance launches, after it provisions it moves into a 'running' state. It moves from 'running' to 'stopped' when you shutdown the instance. Or vice versa when you start the instance back up.
An instance can also be terminated, it is one way - a non reversible action, it is fully deleted.
At a high level EC2 instances are composed of a CPU, Memory, Disk and Networking.
- When an EC2 instance is running you are charged for all 4 of these aspects. It consumes CPU even while idle, it uses memory even when no processing occurs, it's disk is allocated even if unused and additionally networking will be in use.
- When an instance is stopped, No CPU resources are consumed, no memory is used either. So you are not charged for these as it is not running. Also there are no network charges. However storage is still allocated regardless of it's running or stopped. So you will still be charged for EBS Disk Storage if an EC2 is stopped.
Amazon Machine Image (AMI):
An AMI is an image of an EC2 instance.
It can be used to create an EC2 Instance or an AMI can be created from an EC2 Instance.
An AMI can have 3 different permissions settings:
- Public - Everyone can see and use it.
- Owner - Only the owner of the AMI.
- Explicit - Specific AWS accounts are allowed to use it.
Simple Storage Service S3
- S3 is a global storage platform - region resilient (replicated across AZs in a region)
- It is a public service (accessed anywhere via an internet connection) allows for storage of unlimited data and can be used by multiple users.
- Stores nearly all data types Movies, Audio, Photos, Text, Large Data Sets etc.
- Economical Storage solution and can be accessed via the UI / CLI / API & HTTP
- Two main elements to S3 - Objects & Buckets. Objects are the data S3 stores (pictures, videos etc), Buckets are containers for objects.
Objects:
- You can think of objects like files.
- Each object has a key (like a filename) so you can access that particular object in a bucket.
- Each object also has a value - the data comprising the object eg. the data that makes up an image. An object can be anywhere from 0 bytes (empty) to 5TB. This makes S3 very flexible.
Buckets:
- Created in a specific AWS region.
- This means the data inside your bucket has a primary home region.
- S3 Data in a bucket never leaves that region unless you configure the data to leave the region. This means it has stable sovereignty you can keep your data in one specific region ensuring it stays under one set of laws.
- If a major failure occurs (natural disaster or large scale data corruption) S3 impacts will be contained to the region the bucket is in as data doesn't leave it's region without configuration.
- Every bucket has a name and it has to be globally unique (across all AWS accounts and buckets). If any other AWS account anywhere in the world has created a bucket no other bucket can have the same name.
- A bucket can hold an unlimited number of Objects. It is infinitely scalable.
- Buckets have a flat structure - all objects are stored at the same level (no nesting)
- Objects in a bucket can be named using prefixes (/pic/cat1.jpg, /pic/cat2.jpg, /pic/cat3.jpg) the bucket will recognise these cat jpgs as related and present them in a folder called 'pic' (however this isn't a real file structure the bucket structure is still flat).
Important info for CSA Exam:
- Bucket names are globally unique.
- Bucket names have 3-63 Characters, all lowercase, no underscores.
- Bucket names start with a lowercase letter or a number.
- Bucket names can't be IP formatted e.g. 1.1.1.1
- An account is limited to 100 buckets but this can be increased to 1,000 using support requests (1,000 is a hard limit).
- Unlimited number of objects in a bucket with each object ranging from 0 bytes to 5TB.
S3 Patterns and Anti Patterns:
- S3 is an object store - not file or block
- You can't browse S3 like you would a windows file system and you can't mount an S3 bucket like you would a drive.
- S3 is great for large scale data storage, distribution or upload.
- Great for 'offload' - Say you have a blog with lots of images and data you can keep this data in an S3 bucket rather than on an expensive EC2 instance and configure your blog to point users to S3 directly.
- It is the Default INPUT and/or OUTPUT to MANY AWS products. Most of the time the ideal storage solution for an AWS service is S3 (useful for the exam)
CloudFormation Basics
Tool which lets you create, update and delete infrastructure in AWS in a consistent and repeatable way using templates.
A CloudFormation template is written in either YAML or JSON.
CloudFormation Templates:
- All templates have a list of resources. This tells CloudFormation what to do. The resources section is the only mandatory part of a template.
- AWSTemplateFormatVersion this can come at the start of a template and is used to specify the template version. If it is omitted then the version will be assumed.
- Templates can have a description section, this allows the author to note down what the template is for and what it does. This is to help other users of the template. If there is a description section it must follow the AWSTemplateFormatVersion.
- Templates can have a metadata section, this controls how things will be set out in the Console UI.
- The Parameters section allow you to add fields which users must enter information into in order to use the template (eg. Instance Size?)
- Mappings section allows you to create lookup tables.
- The Conditions section allows decision making in the templates. You can set certain things that will only occur if the condition is met.
- The Outputs section is what the template should return once the template is finished being used by CloudFormation.
When you give a template to CloudFormation it creates what is known as a Stack. This Stack is a logical representation of the resources specified in the template. Then for each logical representation of a resource in the stack CloudFormation creates a matching physical resource within your AWS account.
You can adjust a template, when you do the Stack will change and so CloudFormation will adjust the physical infrastructure to match.
You can also delete a stack in which case CloudFormation will adjust physical infrastructure to match (by deleting them).
CloudFormation allows you to automate infrastructure. It can also be used as part of change management.
Cloudwatch Basics
This Collects and manages operational data.
Cloudwatch performs 3 main jobs:
- Metrics - CW monitors + stores metrics and can take actions based on them. These are Metrics from AWS products.
- Cloudwatch Logs - Storing and taking actions based on logs from AWS Products.
- Cloudwatch Events - Takes an action based on a specified event or takes an action based on a set time.
Cloudwatch can also work with non-AWS products, this has to be configure via the CloudWatch Agent. You can use CloudWatch to collect and manage data even from a different cloud platform.

Based on what data Cloudwatch stores:
- It can be viewed via the console
- Can be viewed via the CLI
- Can take an action eg. autoscaling EC2 instances based on usage.
- Can send an alert email via SNS
- + A lot more
CloudWatch Definitions
- Namespace These are a way of separating data with in CloudWatch, they contain related metrics.
- Metrics are a collection of data points in a time ordered structure. Eg. CPU Usage, Network IN/Out, Disk IO.
- Datapoints - for instance every time a server reports its CPU Utilisation that data goes into the CPU Utilisation metric. Each time CPU Utilisation is reported by the server that individual report is called a datapoint. Datapoints feed into metrics.
- Dimensions - These separate datapoints for different things within the same metric. Say you have 3 EC2 instances reporting CPU Utilisation every second and that data is going into the AWS/EC2 Namespace. Each of these EC2 instances will also send 'dimensions' key value pairs like the EC2 instance ID and the type of instance. This allows us to view datapoints for a particular instance.
So using the above you can take as shallow or as deep a look at data as you like. You can go into the AWS/EC2 namespace, choose to look at EC2 CPU Utilisation metric within that Namespace , see individual datapoints. From there you could drill down into the dimensions to see specific data for each EC2 instance.
CloudWatch Alarms
Alarms allow CloudWatch to take actions based on Metrics.
Each alarm is linked to a particular metric. Based on how you configure the alarm CloudWatch will take actions when you deem it should.
For instance a billing alarm with a criteria of 'If monthly estimated bill is > $10' could be configured to send an email to the account owner should that criteria be met. CloudWatch can take a lot more actions than just sending emails.
Route 53 Basics
Provides 2 main services:
- Allows you to register domains
- Can host zones on managed nameservers
It is a Global Service with a single database. So you don't need to pick a region when using it. It is globally resilient.
IAM, Accounts and AWS Organisations
IAM Identity Policies
These are a type of policy which get attached to identities in AWS. Identities are IAM Users, Groups and Roles.
Identity Policies also known as Policy Documents are created using JSON. They are a set of security statements governing permissions and access for an identity within AWS.
An identity can have multiple policies attached to it.
Identity Policy Statement Structure:
"Statement": [
{
"Sid": "FullAccess",
"Effect": "Allow",
"Action": ["s3:*"],
"Resource": ["*"]
}
- First is the Statement ID or SID this is an optional field which lets you identify a statement and what it does. This just lets us inform the reader of what this statement actually does.
- Effect - this is either "Allow" or "Deny" this dictates what AWS does based on the action and resource section of the statement. If the action and resource conditions fit then the effect will come into play.
- The action refers to what the statement affects. It can be very specific, the syntax is service colon operation. You can see in the example "s3:*" the service is s3 then there is a colon followed by * meaning all operations.
- Resources refers to specific resources to be affected by the statement.
So you can see in the above statement example, the Effect is "Allow", the action is any action taken on s3 and the resources are all resources (* means all). So if the identity with this policy attached tries to do anything on s3 with any resource it will be Allowed.
It is possible to have contradictory statements within a policy. Understanding how these work is important for AWS security and for the CSA exam. Lets say we have the above example statement allowing full access to S3. In the same policy document we have the following statement:
{
"Sid": "DenyBucket",
"Action": ["s3:*"]
"Effect": "Deny"
"Resource": ["arn:aws:s3:::mypics", "arn:aws:s3:::mypics/*"]
}
Both of these example statements combined are contradictory. The first gives full permissions for s3 to an identity, essentially administrator access. The second denies access to a specific bucket "mypics". So how does AWS reconcile a policy which both gives an identity full access to s3 in one statement and restricts a small portion of s3 in another statement. (Don't worry if you don't yet understand the Resource syntax in the second statement).
AWS reconciles contradictory policies with a few consistent rules:
- Explicit Deny - If there is a statement with the effect "Deny" then that statement always wins. It overrules all others. In the example policy with the two statements above accessing the "mypics" bucket is explicitly denied, that's it nothing overrules so an identity with this policy could not access "mypics".
- Explicit Allow - If there is a statement explicitly allowing something, as in our first statement allowing all access to S3. Then that statement will take effect, UNLESS there is another statement in the policy contradicting the allow with an explicit deny.
- Default Deny - If there is no statement for an action in an identities IAM policy (Deny or Allow) then that action is denied by default. This is an implicit deny AWS assumes to deny permissions as it has not been explicitly told what to do. All identities start off with no access to AWS resources because of this. If explicit access is not given then permissions are denied by default.
This is very important to remember Deny, Allow, Deny (implicit) the order of importance in IAM policy documents.
In the above example the User would be allowed to access all of s3 except any actions involving the specified "mypics" bucket and any objects within it.
As well as contradiction within a single policy it is possible for there to be a contradiction between two separate policy documents. This needs to be reconciled as an identity can have more than one policy document attached. Lets take User1:
- User1 has Policy-A and Policy-B directly attached to their identity
- User1 is also part of an IAM Group for developers as User1 is a developer. This group has it's own policy doc: Policy-C
So User1's actions and permissions are governed by 3 separate policy documents. AWS reconciles any contradictions between these in the same way it would with a single policy document. It gathers all of the policy documents for an identity and looks at them as one entity. It follows the consistent rules of Deny, Allow, Deny (implicit). No policy document takes precedence rather the statements within the policies take precedence based on the Deny, Allow, Deny rules.
If Policy-A explicitly allows something but Policy-C explicitly denies the same thing then the user will be denied permission for that action.
Similarly if none of Policies A, B or C explicitly allow a particular action then that action will be implicitly denied by default.
Two different types of IAM Policy:
Inline - An individual policy document attached to one User / Group. If you wanted to give 3 Users the same permissions using inline it would be 3 separate policy docs. So if you wanted to change anything after you would have to edit all 3 docs.
Managed Policies - A managed policy can be attached (reused for) multiple Users / Groups if you want to edit multiple user permissions then you only need to adjust the managed policy. This is very useful if you have a policy that needs to apply to lots of people as you may need to adjust it at some point and won't want to adjust 50 individual policy docs. These are Reusable and have Low management overhead
So why would you ever use Inline? Generally you only use inline to give a user exceptions to general rules you have in managed policies.
IAM Users and ARNs
IAM Users are an identity used for anything requiring long term AWS access eg. Humans, Applications or service accounts.
ARNs | Amazon Resource Names - These uniquely identify resources within any AWS accounts. These are used in IAM policies to give or deny permissions to resources.
ARN syntax:
arn:partition:service:region:account-id:resource-id
arn:partition:service:region:account-id:resource-type/resource-id
ARNs are collections of fields split by a colon. A double colon means no field specified.
The first field is the partition, this is the partition the resource is in. For standard AWS regions this is AWS, this will normally always just be 'aws'.
The second field is service, this is the service name space to identify a particular AWS service eg. s3, iam, rds.
The third field is region, the region your resource resides in. Some services do not require this for ARNs.
The fourth field is account-id, the account-id of the AWS account that owns the resource. Some resources do not require this to be specified.
The final field is resource-id or resource-type.
Example:
arn:aws:s3:::mypics # This arn references an actual bucket
arn:aws:s3:::mypics/* # This references anything in the bucket but not the bucket itself
The two immediately above ARNs do not overlap. If you want to allow access to create a bucket AND allow access to objects within that bucket then you would need both types in a policy.
In these ARNs you also notice that there are two double colons where region and account-id would normally go. These do not need to be specified with s3 buckets as bucket names are globally unique
Important IAM information for CSA Exam:
- Limit of 5,000 IAM Users per account. - if you have a need for more than 5,000 identities you would use Federation or IAM Roles (more on those later)
- An IAM User can be a member of 10 IAM Groups at maximum.
IAM Groups
IAM Groups are containers for Users. They exist to make managing large numbers of IAM Users easier. You cannot log in to a group they do not have any credentials.
Groups can have policies attached to them. They can either be inline policies or managed policies. There is also nothing to stop individual IAM Users within a group having their own separate policy documents.
There is no limit to how many Users can be in a group. However as there is a limit of 5,000 IAM Users per account the maximum number of Users that can ever be in a group is 5,000.
There is no default All-Users IAM Group, you could create this yourself to hold all of the IAM Users and apply policies to them but it won't be included automatically.
You cannot nest Groups, there are no Groups within Groups.
IAM Roles
IAM Roles are a type of identity which exists within an AWS account. The other type of identity is an IAM User. IAM Groups are not their own identity - they just contain users.
An IAM Role is generally used by an unknown number or multiple principals (people, applications etc.). This might be multiple users inside the same AWS account or humans, applications or services inside / outside the AWS account.
Roles are generally used on a temporary based, something or someone assumes that role for a short time. Roles are not something which represent the user rather they represent a level of access within an AWS account. A Role lets you borrow permissions for a short period of time.
While IAM Users and Groups can have inline and managed policies attached, IAM Roles have two different types of policy that can be attached:
- Trust Policy - Controls which identities can assume a role. If Identity-A is specified as allowed in the Trust Policy attached to a role then Identity-A can assume that role.
- Permissions Policy - Defines what permissions a role has and what resources can be accessed (similar to an IAM User policy document)
When an identity assumes a role AWS generates temporary security credentials for that role. These are time limited. Once they expire the identity will need to renew them by reassuming the role. These security credentials will be able to use what ever services and resources are specified in the permissions policy.
When you assume a Role the temporary security credentials are created by the Secure Token Service (STS) the operation it uses to assume the role is sts:AssumeRole.
Because roles can allow access to external users, they can also be used to allow access between your AWS accounts.
When to use IAM Roles
For AWS Services:
One of the most common uses of Roles within an AWS account are for AWS services themselves. These services operate on your behalf and they need access rights to perform certain functions.
For example you may need to give AWS Lambda permissions to interact with other AWS services in your accounts. To give Lambda these permissions you can create what is called a Lambda Execution Role which has a trust policy which trusts the Lambda Service to assume the role and a permissions policy which grants access to AWS products and services.
If you didn't use a role in this instance then you would need to hard code access keys into each Lambda Function you wanted to use. This is a security risk and it causes problems if you ever need to change or alter the access keys. Additionally you may be using a single Lambda Function or running many of the same function simultaneously. As the number of principals (people, services etc.) is unknown in this case it is best to use a Role.
For Emergency or Unusual Situations:
When someone may need to assume greater permissions than they currently have in exceptional circumstances. All actions they use the role for will be logged and can be reviewed.
When adding AWS to an existing Corporate environment:
If an organisation already has an identity provider like Microsoft AD they may want to offer single-sign-on with these pre-existing identities to include AWS. In that case you can use roles to allow what is an "external user" access to the companies AWS resources.
Another case may be where a company implementing AWS has more than 5,000 identities, you cannot give each one an IAM User as that would be over the limit. In this case you may give these pre-existing identities access to a role so that they can use AWS resources with set permissions.
For architecture for a mobile app:
A mobile application with millions of users needs to store and access data within an AWS database. You can give users of that mobile application access to an IAM Role which gives them the ability to pull data from an AWS database into the app. This is also really useful because as there are no permanent credentials involved with a role there is no chance of AWS credentials being leaked. This allows you to give potentially millions of identities controlled access to AWS resources.
AWS Organisations
A product which allows businesses to manage multiple AWS accounts in a cost-effective way with very little management overhead.
- First you take a single AWS account.
- With it you create an AWS Organisation.
- That account now becomes the Management Account for the organisation. (It used to be called the 'Master Account').
- Using the management account you can invite other existing accounts to the organisation.
- If those account approve the invite they become part of the organisation.
- These account are now known as Member Accounts of that organisation.
- Before joining the organisation the member accounts had their own separate billing methods and bills.
- Organisations consolidate billing of all accounts in the management account (sometimes known as the payer account).
- This means there is now a single monthly bill that covers all of the accounts within the AWS Organisation, this removes a lot of billing admin.
- Additionally some resources get cheaper the more you use and as organisations consolidate billing they are able to benefit more from these volume discounts than any single account would by itself.
You can also create a new account directly within an Organisation.
Organisations change the best practice in terms of user logins and permissions, instead of having IAM Users in every AWS account you have IAM Roles to allow user to access multiple accounts. The architectural pattern is to have a single AWS account contain all of the identities which are logged into, and then use Roles to access other accounts with in the Organisation.
- Organisations have a root container - This is the container for all elements in the organisation.
- Below this there are organisational units OU - These are groupings of accounts, often those that perform similar functions. You might put all of your developments accounts in one OU.
- Organisational Units can be nested so within the Development OU you may have a DevTest OU (containing relevant AWS accounts) and a Staging OU (containing relevant AWS accounts)
- Below that level you have AWS Accounts, these can be outside or inside an OU.
Service Control Policies (SCP)
SCPs are JSON policy documents which can be attached to an organisation as a whole. They can also be attached to one or more organisational units or they can be attached to individual AWS accounts within an organisation.
The Management Account of an Organisation is never affected by service control policies. As the management account cannot be restricted using SCPs it is often a good idea to never use it to interact with AWS resources and instead use other accounts within the organisation which can be permission controlled by an SCP.
SCPs are account permissions boundaries. They limit what accounts (and therefore IAM identities within) are allowed to do, in doing so they can also limit what an account root user can do. This may seem strange as an account root user is not able to be restricted, but you are not directly limiting the root user. Rather think of an SCP as limiting what the account itself can do. The root user of that account still has full permissions to do anything the account can do but if the account can't do something due to an SCP then the root user can't do it either.
Service Control Policies do not grant any permissions - They merely define permission boundaries, they establish which permissions can be granted within an account. you would still need to give identities within accounts permissions to access resources, Any SCPs attached to the account have the ability to limit the permissions that can be given to those identities.
SCPs follow the standard permissions rule of Deny, Allow, Deny (implicit). If something is explicitly denied in a Service Control Policy but is contradicted by an explicit allow in the same SCP or another one then the Deny will always take precedence. If something is not explicitly allowed then it is implicitly denied.
When you first create an SCP Amazon automatically adds a statement to explicitly allow everything - this can be removed or altered.
For example let's say you create an SCP within an account that grants access to only s3, EC2, RDS and IAM. You then create an IAM Identity with an attached policy that allows access to s3, EC2 and Route 53. The SCP defines the permission boundary of the account and supersedes the IAM policy - so the IAM identity would only have access to s3 and EC2 as access to Route 53 is not explicitly allowed by the SCP

CloudWatch Logs
- Public Service - usable from AWS or on-premises (or even other cloud platforms).
- Allows you to store, monitor and access logging data.
- Has built in AWS Integrations including - EC2, VPC, Lambda, CloudTrail, Route 53 etc.
- Can generate metrics based on logs - known as a metric filter - these look for specific elements in logs and picks them out to graph them as data points. Eg. Setting a metric filter to look for errors in your CloudWatch Logs.
- Cloud watch logs is a regional service (not global).
CloudTrail
- CloudTrail is a service that logs API actions which affect AWS accounts. Eg. stopping an instance, deleting an s3 bucket it's all logged by CloudTrail.
- Almost everything that can be done in an AWS account is logged by this service.
- Logs API calls as a CloudTrail Event. Each of these is a record of an activity within an AWS Account.
- Stores 90 days of even history.
- Automatic 90 day store Enabled by default and at no cost.
- You can see all the actions taken in the last 90 days in your CloudTrail Event history.

- To see your CloudTrail Events beyond this 90 day history you need to create a 'Trail' to store the event history.
- CloudTrail events can be one of two types Management Events and Data Events.
- Management events are things like creating an EC2 instance, terminating it, creating a VPC
- Data events contain information about resource operations performed on in or in a resource. Eg. Uploading or accessing objects from s3.
- By default CloudTrail only stores Management events as Data events tend to be much higher volume.
A CloudTrail Trail is how you provide configuration for how CloudTrail should operate beyond default. Trails can be set to single region or all regions. A regional trail would only log regional Events in its own region. This means a regional Trail may not log events in a global service like CloudFront. This is because global services like CloudFront and IAM always log their events to the same one region US-East-1. An all regions Trail encompasses all regions and is automatically updated as regions are added by AWS.
An all regions Trail with global services event logging enabled is listening to all Management events in the account. If you then enable Data event logging for the Trail it will be listening to everything that is happening in the account.
A Trail can store events in a specified s3 bucket, this is how you can keep event history beyond 90 days. When CloudTrail Event logs are stored in s3 they are stored as compressed JSON formatted documents that take up hardly any space.
CloudTrail can also be integrated with CloudWatch logs. CloudWatch logs can then be used to analyse the data with metric filters.
CloudTrail can also have an organisational Trail. This is where one trail logs all of the events in your entire organisation (multiple accounts). Rather than having to set Trails on each account in your org, you can use this.
CloudTrail Need to Knows for the Exam
- Enabled by default but only logs last 90 days
- Trails are how you can configure the data in CloudTrail to be stored in s3 and CloudWatch
- CloudTrail by default only stores Management Events
- Some truly Global Services always log their events to one specific region US-East-1. A regional Trail outside US-East-1 would not capture these events.
- CloudTrail is NOT Real Time - there is a delay (15 mins or so)
S3: Simple Storage Service
S3 Security
S3 is private by default. The only identity that automatically has access to a bucket is the account root user of the account the bucket was created in. Any other permissions have to be explicitly given.
One way to give these permissions is using an S3 Bucket Policy which is a form of resource policy. A resource policy is just like an identity policy but it is attached to a resource instead eg. an s3 bucket.
Differences between identity policies and resource policies:
Where identity policies control what an identity can access, resource policies control who can access the resource. A major difference between the two is that identity policies can only ALLOW or DENY an identity access to resources and actions with in a single account. You have no way to give the identity access to resources in another account. Resource policies can ALLOW or DENY actions and access from the account they are in or completely different accounts. This makes resource policies a great way to control access to particular resource no matter what the source of the access is.
Resource Policies can also ALLOW or DENY Anonymous principals. You CAN'T attach an identity policy to nothing - it always needs an identity to attach to. A resource policy CAN allow complete open access to a resource even if there are no AWS Credentials to assign that ALLOW to. This means a resource policy can allow anonymous non-aws authenticated principals access to a resource.
Resource policies (therefore S3 Bucket Policies) have a Principal which needs to be specified. This principal is who or what the policy is allowing or denying access to. When writing an identity policy you do not need to specify a principal as it is assumed the identity to which the policy is attached is the principal. This means you can identify a resource policy or an identity policy by whether or not it has a principal specified.
{
"Version": "2012-10-17"
"Statement": [
{
"Sid":"PublicRead",
"Effect": "Allow",
"Principal": "*",
"Action": ["s3:GetObject"],
"Resource": ["example:arn:s3::addweflkwf/*]
}
]
}
Above is an example of a resource policy - you can see that there is a principal specified "*" meaning all principals. So any principal can perform the action "s3:GetObject" on the resource specified by this policy.
You can use s3 bucket policies to provide very granular access to s3 based on a variety of factors. You block access to a particular folder, based on identity, IP address, whether your identity uses MFA and more. These policies can be very simple or they can get quite complex.
There can only be one bucket policy attached to a bucket. If an identity accessing a bucket also has an identity policy attached then the access rights to the bucket will be the cumulative effect of the identity policy and the resource policy based upon Explicit DENY, Explicit ALLOW, Default DENY - as discussed earlier.
S3 buckets also have a Block Public Access setting - these settings are configured outside of s3 bucket policies and only apply to anonymous principals. They apply no matter what the bucket policy says. This way if you accidentally configure your bucket policy to allow public access and didn't mean to but you have correctly configured your Block Public Access setting then your mistake won't lead to data leaks.
s3 Static Website Hosting
When we use S3 on the console we are actually accessing it via API. The console is just a visual wrapper for the underlying API. When we access an object in the s3 console we are really using the underlying GetObject API command.
We can use s3 to host static websites which instead of accessing s3 via API allows us to access it via HTTP. When you enable this feature on a bucket AWS creates a Website Endpoint which the bucket can be accessed at via HTTP.
This feature allows you to offload all of the media on a website to s3 - s3 is a far cheaper form of storage than keeping it on a compute service like EC2.
Pricing
- S3 charges a per GB month storage fee. So every Gigabyte you have stored each month incurs a charge, if you pull the data before the month is up then you only pay for the portion of the month you used.
- There are also data transfer charges. You are charged to transfer data OUT of s3 (per GB) but you are never charged to transfer it INTO s3.
- You are also charged a certain amount to request data. If you are hosting popular static website using s3 then you may use a lot of requests .
S3 Object Versioning and MFA Delete
These are important to know for the solutions architect exam.
Object versioning - is configured at the bucket level. It is disabled by default, once enabled you cannot disable it again. You can suspend versioning on a bucket and then enable it again but you can't disable it. Suspending versioning just stops new versions being created but it does not delete existing versions. Versioning lets you store multiple versions of an object within a bucket. Any operations / actions which result in a change to an object generate a new version of the object and leave the old one in place. Without Versioning enabled the old object is just replaced by the new one.
Objects have both a KEY (its name eg cat-pic.jpg) and an ID which when Versioning is disabled is set to null. If you have versioning enabled and you have cat-pic.jpg in you bucket, it will be given an ID number. If you now uploaded another cat-pic.jpg rather than deleting the existing cat-pic.jpg and replacing it with this fresh upload, the new upload will be given a different ID and the original cat-pic.jpg will remain.
The newest version of an object in a versioning enabled bucket is known as the current version. If an object is accessed / requested without explicitly stating the ID of the object then it is always the current version that will be returned. However you have the option of specifying the ID to access a particular version of an object.
Versioning also impacts deletions - if you delete a versioned object it is not actually deleted. Instead AWS creates a new special version of the object called a delete marker essentially this hides all previous versions of the object and in effect deleting it. You can however delete the delete marker which then effectively undeletes all the previous versions of the object.
It is possible to actually delete an object completely. All you have to do is specify the ID of the object you want to delete. If the ID is for the current version then the previous version will be promoted to current version.
MFA Delete - A configuration setting for object versioning that when enabled causes MFA to be required to change any versioning state. Eg when making a bucket go from disabled -> enabled or enabled -> suspended for versioning.
- Can also require that MFA is used to delete any versions from a bucket.
S3 Performance Optimisation
Single Put vs Multipart Upload
- By default when you upload to S3 it is uploaded in a single blob, as a single stream. This is a Single Put Upload.
- This means if a stream fails the whole upload fails. If you need to upload from somewhere with unreliable internet this is a negative.
- A Single Put Upload is limited to 5GB of data.
The solution to this is using multipart upload. It does this by breaking data up into individual parts. The minimum amount of data to use multipart upload is 100mb. An upload can be split into a maximum of 10,000 parts ranging between 5MB and 5GB. The last part of data (leftover) can be smaller than 5MB if needed.
- Each individual part is treated as its own isolated upload which can fail and be restarted as an individual up load. This means if you were uploading 4.5GB of Data and one part fails the whole upload doesn't fail, you can just restart that one failed part saving time and money.
- Additionally this multipart upload massively improves Transfer Rate as the upload speed is sum of the speed of all the different parts being uploaded. This is much better than Single Put Upload where you are limited to the speed of the single stream.
S3 Transfer Acceleration
Without Transfer Acceleration if you were sending data from Australia to a bucket in the UK the data will travel over the public internet taking a route determined by ISPs - not necessarily the quickest route and often slowing down in areas as it hops across the globe to its final destination in the UK. This is not optimal.
Transfer Acceleration uses AWS's network of edge locations around the world. In this case if you were uploading data in Australia to a UK S3 bucket the data you upload would be routed to the nearest edge location (still over the public internet but a much shorter distance) from there the data is sent to the destination S3 bucket over the AWS network using a much quicker and more direct route.
The results of this are more reliable and higher performing data transfers. These benefits improve more the larger the distance between the upload location and destination location.
Encryption Basics
Encryption Approaches
- There are two main approaches to encryption utilised with in AWS and the wider world. Encryption At Rest and Encryption In Transit
Encryption At Rest
- Encryption At Rest is designed to protect against physical theft and physical tampering.
- An example of this is an encrypted laptop - the laptop encrypts data as it writes to the disk and decrypts it as it reads it when required.
- This encryption and decryption is done using whats known as a 'secret' eg. The password of the user logging into the laptop
- If this laptop were stolen but they don't have the secret they have no access to the data.
- Encryption At Rest is commonly used in cloud environments. Often your data is stored on shared hardware but it is encrypted at rest.
Encryption In Transit
- Encryption in Transit is designed to protect data at it flows from one location to another.
- Data is encrypted before it leaves a source and it is encrypted in transit and then it is decrypted at the destination.
Encryption Concepts
- Plaintext - this may seem obvious but actually even though the name implies it is text data it isn't always. Plaintext is any unencrypted data, it can be text, images, videos etc.
- Algorithm - a piece of code / maths which takes plaintext and an encryption key and generates encrypted data.
- Key - a password (can be more complex than that) used by the Algorithm during encryption.
- Ciphertext - The output of an Algorithm using plaintext and a key to encrypt plaintext. Ciphertext is any encrypted data (again not just text)
Types of Key
The type of key used impacts on the how encryption and decryption of data functions.
Symmetric Keys used in Symmetric Encryption:
- The sender of the data generates a symmetric key and keeps it private. This key is used by an algorithm to encrypt the data and output it as ciphertext. Nobody can decrypt this ciphertext now without the key, it can be sent over a network without risk. However a problem occurs when the receiver of the data has to decrypt it as they need the same key to decrypt the data. This means you now have to find a way to safely send the key to the receiver as well (difficult). This is why symmetric encryption is great for local encryption and disk encryption but not so great for sending encrypted data between two parties.
Asymmetric Keys used in Asymmetric encryption:
- An asymmetric algorithm is used and a pair of keys is generated a public key and a private key. The public key can be used to create ciphertext that can only be decrypted by the private key. You can give anyone the public key (make it public) and as long as the private key is kept private only you will be able to decrypt the data they send you that has been encrypted by the public key. This gets around the problem of key exchange that symmetric encryption has. Asymmetric Encryption is generally used when two or more remote parties are involved.
Asymmetric Encryption is much more computationally expensive than symmetric encryption. So sometimes people use Asymmetric Encryption only initially to agree on a key to use for symmetric encryption in future.
Signing
A process that uses Asymmetric Encryption. Signing solves the issue that anyone can encrypt messages and send them using asymmetric encryption as the public key is not private. Encryption does not prove identity. If system 1 is waiting on an encrypted response from system 2 how can it be sure that the response it receives is actually from system 2. Anyone with the public key can send a message using the public to system 1. So system 1 needs a way to ensure that the encrypted message is actually from system 2.
Signing can prove identity using the inverse process of asymmetric encryption (but still using asymmetric encryption). Imagine:
- Derek is sending a message to Jenny.
- Derek uses Jenny's public key to encrypt the message before sending it.
- Now only Jenny will be able to read the message as she is the only one with the private key for that public key.
- But how will Jenny know that it is actually Derek sending the message?
- Well, Dereks "signs" the message with his own private key (from a separate key pair to Jenny's).
- Jenny receives the message and decrypts it using her private key - she can see it has been signed so she uses Derek's public key (from Derek's own Public/Private key pair) to check that the signing was indeed done by Dereks private key. This proves it is Derek who sent the message as only he has access to the private key that did the signing.
- You can use the public key to prove that a private key signed something and this is how signing works.
Key Management Service KMS
This is not a service that is specific to S3, but it is used in most AWS services that use encryption. S3 is one of those so it is important to understand KMS.
- KMS is a regional and a public service
- It lets you create store and manage cryptographic keys
- Capable of creating symmetric and asymmetric keys
- KMS can perform many cryptographic operations - including encryption, decryption and others.
- Keys are isolated to a specific region & never leave KMS - It provides FIPS 140-2 (L2) compliancy which is a US security standard (sometimes comes up in SAA Exam).
- The main thing that KMS manages are CMKs (Customer Master Keys)
- These are used by KMS within Cryptographic operations - you can use them, applications can use them and other AWS services can use them.
- CMKs are logical - think of them as containers for the actual keys.
- CMKs contain an ID (unique identifier for the key), creation date, key policy, a description and a state of the key (active or not)
- Every CMK is backed by physical key material (Actual Keys) for encryption and decryption of data.
- CMKs can be used to directly encrypt of decrypt data that is a maximum of 4KB in size. (Important for Exam)
- This may seem like quite a big limitation but KMS offers other services that make this 4KB limit not so important.
CMKs can be AWS Managed or Customer Managed. AWS Managed CMKs always use a standard key policy (defining access etc) whereas Customer Managed allows you to write your own key policy. AWS Managed has a default Key Rotation of 1095 days, Customer Managed CMKs can have rotation on or off, on defaults to rotation every 365 days.
When you create a key with KMS a CMK is created by the service to contain the physical key material. This CMK is encrypted by KMS before it is persistently stored, CMKs are never stored unencrypted.
Data Encryption Keys: How KMS gets around the 4KB limit.
- Data Encryption Keys (DEKs) are another type of key that KMS can generate.
- DEKs are generated using a CMK.
- These DEKs can be used to encrypt data larger than 4KB in size.
- Each DEK is linked to a specific CMK.
KMS does not store the DEK in anyway it provides the Data Encryption Key to you and then throws it away. This is because KMS does not actually do the encryption and decryption of data above 4KB itself, you do that or the service using KMS does it.
When KMS creates a Data Encryption Key it provides you with a plaintext version and a ciphertext version (encrypted by the CMK). You would then use the plaintext DEK to encrypt your data, immediately then destroying this plaintext DEK. When you need to decrypt your data you provide the encrypted DEK to KMS which uses the CMK to decrypt it so you can then in turn decrypt your data with the decrypted DEK.
Services like S3 generate a DEK for every single object. They encrypt the object and then discard the plaintext version.
S3 Object Encryption
One key thing to understand is that Buckets are not encrypted it is the Objects inside them that are encrypted (There is something called Bucket Default Encryption, but that is different and still not bucket level).
You define encryption at an object level and each object in a bucket could be using a different type of encryption.
Within S3 there are two main methods of encryption:
Client Side Encryption - The objects being uploaded are encrypted by the client before they ever leave. The data is received by AWS encrypted.
Server Side Encryption - The objects aren't initially encrypted. They are encrypted in transit after leaving the client but at AWS it comes out unencrypted until is is encrypted by the S3 infrastructure.
Both of these refer to encryption at rest not encryption in transit. Encryption in transit comes as standard with S3.
Types of S3 Server Side Encryption:
SSE-C - server side encryption with customer provided keys.
SSE-S3 (AES256) - server side encryption with Amazon S3 Managed. - Each object has a unique key generated by S3.
SSE-KMS - server side encryption with Customer Master Keys (CMKs) stored in AWS KMS. - Allows for role separation, someone with full access permissions to S3 can't read your data unless they also have KMS permissions over the CMK used to encrypt the S3 objects.
Default Bucket Encryption: You set a default form of encryption for a bucket's objects eg. AES256 or aws:kms. Then in future if you don't specify an encryption method when putting an object in a bucket the bucket will still encrypt the object according to the default set. You could always explicitly use a different form of encryption or none at all in spite of this. But you have to be explicit.
S3 Object Storage Classes
S3 Standard
The default storage class is S3 Standard. When an object is stored in this class it is replicated across 3 Availability Zones. This means S3 Standard provides eleven nines of durability. When storing objects if you receive an HTTP/1.1 200 OK response from the S3 API endpoint then you know your object has been stored durably within S3.
You are billed a GB/m fee for data stored, A $ cost per GB for transfer out (IN is free) and a price per 1,000 requests. No specific retrieval fee, no minimum size or duration (isn't true for other classes).
Has a milliseconds first byte latency and objects can be made publicly available.
S3 Standard should be used for frequently accessed data which is important and Non Replaceable.
S3 Standard-IA (Infrequent Access)
Everything is the same above except - the storage costs are much cheaper (about half). Transfer OUT cost is the same, price per 1k requests is the same, still no transfer IN fee. BUT there is a new type of fee a retrieval fee per GB of data. So the costs inflate with frequent access. Also a minimum duration costs each object is billed a minimum of 30 days, they can be stored for less time but billing is always 30 days. Additionally no matter how small the objects you are billed a minimum of 128KB per object.
S3 Standard-IA should be used for long lived data which is important or irreplaceable but where access is infrequent.
S3 One Zone-IA
Similar to S3 Standard-IA but is cheaper than both Standard and Standard-IA. The big difference between One Zone-IA and Standard-IA is that there is no data replication to other AZs. You do still get eleven nines of durability as data is still replicated within the AZ but this durability does assume the AZ won't fail. All other costs between Standard-AI and One Zone-AI remain the same.
S3 One Zone-IA should be used for long lived data (as still has same size and duration minimums as Standard-IA) which is non-critical or replaceable and where access is infrequent.
S3 Glacier
Same 3 AZ architecture at S3 Standard - it has a storage cost about 1/5th of Standard. Think of objects stored this way as cold objects, they aren't warm and they aren't ready for use. They aren't immediately available and can't be made public. To get access to them you need to perform a retrievable process which has a cost. There are 3 types of retrieval process costed to how fast they are:
Expedited - Available in 1-5 minutes
Standard - Available in 3-5 hours
Bulk - Available 5-12 hours
Glacier has a first byte latency of minutes or hours. Glacier has 40KB minimum size and 90 day minimum duration.
S3 Glacier should be used for Archival data where frequent or realtime access isn't needed and you don't mind Minutes-hours for retrieval.
S3 Glacier Deep Archive
About 1/4th the price of Glacier. If normal glacier is data in chilled state deep archive is data in a frozen state. Glacier DA is 180 minimum duration and 40KB minimum size.
Retrieval times are a lot longer:
Standard - 12 hours
Bulk - 48 hours
S3 Glacier Deep Archive should be used for Archival Data that rarely if ever needs to be accessed - hours or days for retrieval.
S3 Intelligent Tiering
Contains four different tiers of storage:
Frequent Access Tier
Infrequent Access Tier
Archive
Deep Archive
This intelligently judges your objects and moves them between tiers based on access regularity - you can configure this. It will only use the archive tiers if you ask it too based on configurations.
The costs for the tiers are the same as the class they relate to. There is also a management fee for the intelligent tiering capacity.
S3 Intelligent Tiering should be used for long-lived data, with changing or unknown patterns.
S3 Lifecycle Configuration
- A Lifecyle Configuration is a set of rules
- These rules consist of actions on buckets or a group of objects
- Transition Actions - eg. transition an object from S3 Standard to IA after 30 days and then from IA to Glacier after 90 days.
- Expiration Actions - Delete an object or version of an object after a set amount of time.
- These rules are not based on access - only time.
Transition Actions can flow downwards only - from Standard to IA, Glacier, Deep Archive etc. You have to be careful with Transition Actions as other classes can have minimums on size and duration meaning you could end up with higher costs if you transition the wrong objects (eg. lots of small ones).
Additionally there is a 30 day minimum that an object has to stay on S3 Standard before it can be transitioned (by a Transition Action) to any infrequent access class.
S3 Replication
Two types of replication available on S3:
Cross-Region Replication (CRR) - Allows for replication from a source bucket to a destination bucket in different AWS Regions.
Same-Region Replication (SRR) - Same process but where the source and destination buckets are in the same AWS Region.
In both types the source and destination buckets could be in the same or different AWS Accounts.
You can either replicate an entire bucket or using a rule you can define a subset of objects to replicate. The default storage class is the same as source bucket but you can also specify which storage class to use - for instance as it is a copy of data you could use One Zone IA for the destination bucket.
Important for exam:
- Replication is not retroactive - only from when you turn replication on will those objects be replicated across.
- In order to enable replication both buckets need versioning enabled.
- One way replication only. Only source is replicated to Destination. If you added to destination it wouldn't be replicated to source.
- Encryption - You can't replicate SS3-C as AWS doesn't have the keys. But it can replicated SSE-S3 & SSE-KMS.
- The owner of the source bucket needs permission for the objects in that bucket.
- No system events, Glacier or Glacier Deep Archive can be replicated.
- DELETES ARE NOT REPLICATED.
Why use replication?
SRR:
- Log aggregation
- PROD and TEST sync across AWS Accounts
- Resilience with strict sovereignty (your data can't leave a region)
CRR:
- Global Resilience
- Reduce Latency for global access
S3 Presigned URLs
Presigned URLs are a way to give someone external temporary access to an object within a bucket. The Presigned URL can be generated by someone with permissions to do so - it will contain the details of the bucket it is for, which object and the user which generated it. It will also be configured to expire at a certain date or time.
When the URL is used the person who uses it is interacting with the specified object as the user who generated the URL.
These URLs can be used for either download (GET) or upload (PUT) operations.
Important Points:
- It is possible to create a URL for an object that you have no access to.
- When using a Presigned URL it matches the current permissions of the identity that generated it. Not the permissions of the identity at the time it was generated.
- Access denied could mean the generating ID never had access or they no longer do.
- Don't generate with a role. Roles are temporary credentials the URL stops working the temporary credentials expire.
S3 Select and Glacier Select
- These allow you to select only parts of objects.
- S3 can store huge objects up to 5TB.
- You often want to retrieve the entire object.
- But retrieving a 5TB object - which takes time and uses 5TB of transfer (cost adds up)
- S3/Glacier Select lets you use SQL-Like statement to select part of an object.
- You can do this on CSV, JSON, Parquet, BZIP2 compression for CSV and JSON.
S3 Events
- When enabled a notificiation is generated when events occur in a bucket.
- The notifications can be delivered to SNS SQS and Lambda Functions.
- This means you can have event driven actions based upon events in S3.
There are a wide range of events and event types:
- Object Created (Includes PUT, POST, COPY, CompleteMultiPartUpload)
- Object Delete (*, Delete, DeleteMarkerCreated)
- Object Restore (Post (Initiated), Completed)
- Replication
VPC: Virtual Private Cloud
VPC Sizing and Structure
Considerations:
- What size should the VPC be.
- Are there any Networks that can't be used.
- Be mindful of ranges that other VPCs use, utilised in other cloud environments, On-Premises networks. Be sure to understand what other ranges your network might need to interact with so you don't clash.
- VPC structure - Tiers and Resiliency (Availability) Zones.
- VPC minimum can be a /28 (16 IPs) network and at most /16 (65456 IPs).
- Avoid common ranges eg. 10.0... 10.1 - Starting at 10.16 will help to avoid most common ranges 10.X... ranges.
- Reserve 2+ networks in each region in each account you use.
- What you would do is look at what ranges you can use that don't clash with existing ranges used by your business or that you might interact with. Then out of these ranges you can assign space to each region and account.
AWS Defined VPC Sizing:

Deciding which of the above types to use comes down to a few questions:
- How many subnets do you need in your VPC.
- How many IP addresses do you need in total.
- How many IP addresses in each subnet.
How many subnets should I use?
- A subnet is available in one AZ, so you need to work out how many AZs you want your VPC to use. Three AZs is a good default + one spare for potential growth in the future. This means a good standard for a VPC is to have 4 availability zones.
- This means you will have to at least split your VPC into 4 smaller networks (More dependent on how many tiers), so if you started with a /16 you will now need at least 4 smaller /18s to take advantage of each AZ
- Then you also need to consider your tiers. You might need a tier for Web, Application, DB and Other/Spare. To make full use of your AZs you will need one subnet for each of these tiers for each of your AZs. This means four of each tier in each AZ, so 16 in total.
- This means in total you will have 16 Subnets, 4 in each AZ so splitting /16 equally between them means you will have 16 /20s.
- You don't need to use /16 but now you know how many subnets you will need you can work out how many IPs you will need for the whole VPC - and subsequently how many in each subnet.
- This is an example - consider your design & circumstances to work out how many AZs you'll need and how many tiers.
Practical Networking: Custom VPCs
- VPCs are a regionally isolated and regionally resilient service - it operates in all AZs within that region.
- Allows you to create isolated networks - within one region you can have multiple VPCs.
- Nothing is allowed in or out without explicit configuration.
- Custom VPCs have a flexible configuration - simple or multi tier.
- Custom VPCs enable hybrid networking - can connect to other clouds and on-prem environments.
- Gives you the option of default or dedicated tenancy. If you choose default you can select at a resource level later on if you want a particular resource to still be on dedicated tenancy.
- VPCs can use IPv4 private CIDR blocks and Public IPs. By default the VPC uses private IPs, public IPs are only used for when a resource needs to communicate with the public internet or the AWS public zone.
- A VPC is allocated 1 mandatory primary private IPv4 CIDR block.
- Optionally you can use a single assigned IPv6 /56 CIDR block (assigned by AWS or ones you already own)
- By default fully featured DNS is available in all VPCs through route53, the DNS address is the base VPC address +2 - eg,. If the base VPC address is 10.0.0.0 then the DNS IP will be 10.0.0.2.
Two critical options for how DNS functions in a VPC:
- enableDnsHostnames - Indicates whether instances within a VPC are given public DNS hostnames. If set to true they do.
- enableDnsSupport - Indicates whether DNS is enabled or disabled within the VPC. Set to true or false.
VPC Subnets
- Subnets inside a VPC start off entirely private and take some configuration to make them public.
- Subnets are AZ resilient.
- They are a subnetwork of a VPC within a particular AZ.
- One subnet is created in a specific AZ, the AZ can never be changed and a Subnet can only ever be in one AZ. However one AZ could have many subnets.
- A subnet is allocated an IPv4 CIDR and this CIDR is a subset of the VPC CIDR.
- The subnet's CIDR cannot overlap with any other subnets in the VPC.
- Subnets can optionally be allocated an IPv6 CIDR (/64 subset of the /56 VPC).
- Subnets can communicated with other subnets in the VPC.
Subnet IP Addressing
- Whatever the size of the subnet there are always 5 reserved IP addresses within it that you can't use. These are reserved.
- The addresses that can't be used in all subnets are:
- The network address (First IP address in the Subnet CIDR block)
- The network+1 address (Second IP in CIDR block) - Reserved for VPC Router
- The network+2 address (Third IP in CIDR block) - Reserved (DNS)
- The network+3 address (Fourth IP in CIDR block) - Reserved for future use
- Broadcast Address (Last IP in the Subnet CIDR block)
- So the IPs that are reserved are the first four in the Subnet CIDR block and the last.
- This means if a Subnet should have 16 IPs, it actually only has 11 useable ones.
DHCP Options Set
A VPC has a configuration object applied to it called a DHCP Options Set. There is one DHCP Options Set applied to a VPC. This configuration then flows through to subnets and controls things like DNS servers.
VPC Routing & Internet Gateway
VPC Routers
- Every VPC has a VPC Router - it moves traffic from somewhere to somewhere else.
- It runs in all the AZs that the VPC uses, it has a network interface in every subnet in your VPC the "network+1" address.
- Main purpose is to simply route traffic between subnets.
- The VPC router is controlled by route tables, each subnet has one.
- Every VPC has a main route table - if you don't explicitly associate a custom route table with a subnet it uses the main route table of the VPC.
- If you do associate a custom route table with a subnet then the main route table is disassociated with it.
- A subnet can only have one route table at any one time - but a route table can be associated with many subnets.
- If traffic leaving a subnet has a destination that matches multiple things in the route table - say it matches route to a specific IP and a network containing that IP then the route with higher specificity will be used, in this case the specific IP.
- Once the destination has been selected based on highest priority match in the route table then the "target" for that route is where the traffic is sent.

- The target will either point at an AWS Gateway or it will say local, local means the destination is in the VPC itself and can be forwarded directly.
- All route tables have at least one route, the local route. This matches the VPC CIDR range. To let the router know that any destination matching the VPC CIDR can be sent directly.
Internet Gateway IGW
- IGW is a regionally resilient gateway attached to a VPC. As it is regionally resilient it will cover all the AZs the VPC is using.
- A VPC can have no Internet Gateways or 1 Internet Gateway.
- It runs from the border of the VPC and the AWS Public Zone.
- It gateways traffic between the VPC and the internet or the AWS Public Zone (S3, SQS, SNS etc.)
- Managed service run by AWS, they handle performance. It just works.
Important: When you configure resources with a public IPv4 address, this public IP is not actually configured on the resource. Rather the Internet Gateway maintains a record that associates that public IP with the private IP assigned to the resource within the VPC. This is why the OS of a server you are using cannot see the public IPv4 address associated with the server itself.
This means an EC2 will send packets with a source listing its Private IP, not it's public IP, once the the packet reaches the IGW the source of the packet is changed to public IP associated with the EC2, at no point is the OS of the EC2 aware of its public IP. For IPv6 the Public IP address is natively configured on resources, the IGW does not do any translation.
Network Access Control Lists (Network ACLs or NACLs)
Stateful vs Stateless Firewalls
- A stateless firewall sees a request and response as two individual parts. When the client sends a request to the server the firewall sees this as distinct and separate from the response sent back by the server. This means rules set in the firewall need to be set for both inbound and outbound if the firewall is stateless.
- A stateful firewall can identify the response to a given request. This means you only have to allow the request or not and the response will allowed or not automatically.
NACLs
- A firewall available within AWS VPCs.
- Every subnet has an associated NACL which filters data as it crosses the boundary of that subnet (both in and out).
- NACLs are only assigned to subnets - they can't be assigned to individual resources.
- One NACL can be assigned to many subnets, but a subnet can only have one NACL.
- NACLs do not affect data moving within a subnet, only leaving or entering.
- NACLs contain rules grouped in INBOUND and OUTBOUND. Inbound rules match traffic Entering, Outbound matches Leaving.
- NACLs are stateless.
- Rules match the Destination IP/Range, Destination Port and Protocol and Allow or Deny based on that match.
- Every VPC is created with a default NACL that ALLOWs all traffic.
When traffic comes into a subnet it is assessed by the NACL for whether it is inbound or outbound traffic and therefore if the inbound or outbound rules should be applied. Once that is complete it begins to apply the rules in order based on lowest rule number. Once a rule match occurs processing is stopped and that rule is applied whether allow or deny. This means if you have two rules matching the same data and the rule with Deny has a lower rule number, then the data will be denied. Additionally if traffic matches no rules there is an implicit deny.
VPC Security Groups
- Security Groups and NACLs share many broad concepts. Both filter traffic within VPCs.
- Security Groups are stateful if an inbound or outbound request is allowed then the response is automatically allowed too.
- There is no explicit DENY the only ALLOW or Implicitly Deny (meaning you haven't specifically set an allow rule that applies)
- This means they can't be used to block specific bad actors. You'd use a NACL for this.
- Support IP/CIDR and Protocol based rules like NACLs but also logically referencing other AWS resources like other security groups and itself.
- Security Groups are not attached to Instances (Even if UI shows it this way) or Subnets they are attached to the Primary Elastic Network Interface of the instances.
- One Security Group can be applied to many instances. Instances can also have multiple security groups (though this risks overlapping rules)
- Just like a NACL security groups have inbound and outbound rules.
As Security Groups can logically reference AWS Resources they give you a lot more flexibility with setting rules. For example imagine you had a web server and an app server in two different subnets both with their own Security Groups. To enable communication between the servers one option would be to set an inbound rule on the APP server for the IP address of the web server over TCP on Port 1234 (for example).
However what about scaling in future, leading to changing IPs and more servers? Well what you could do instead of referencing the IP address of the web server is to set a rule to allow any traffic on TCP Port 1234 from the Web Servers entire security group. Meaning that in future when you scale, as long as the servers use the same security group the traffic will continue to flow interrupted without additional rules.
Another example of added flexibility is that Security Groups allow Self Referencing this means you can create a rule within a Security Group that allows traffic on all ports and protocols with the traffic source set to the SG itself. This means that communication in between all resources governed by the security group is allowed, simplifying intra app communications. This would also mean IP changes are automatically handled which would be useful if the instances were for example in an autoscaling group.
Network Address Translation (NAT) and NAT Gateways
- NAT is a set of processes that can remap and change Sources and Destination IPs.
- NAT is mostly used for IP masquerading - hiding an entire private CIDR block behind a single public IP. This is what the NAT Gateway does.
- This is useful because public IPv4 addresses are running out so giving every resource it's own public IP can be wasteful.
- NAT gives private CIDR ranges outgoing internet access. So resources can send data to the public internet and receive responses, but you could not initiate a connection to these private IPs through NAT.
NAT Gateway
- Product from AWS to allow resources to use NAT within a subnet.
- Needs to run from a public subnet - because it needs to be assigned a public IP to masquerade private IPs behind.
- NAT Gateways use Elastic IPs (Static public IPv4).
- AZ resilient service - for region resilience you would need a NATGW in each AZ in the region subnet.
- Managed service that scales to 45Gbps.
- Charged per hour and additionally charged per GB of processed data.
NAT is not required for IPv6 - In AWS IPv6 addresses are all publicly routable so NAT is not required. NAT Gateways do not work with IPv6. The Internet Gateway works with IPv6 automatically.
EC2: Elastic Compute Cloud (Basics)
Virtualization
EC2 provides virtualisation as a service. Virtualisation is the process of running more than one Operating System on a single piece of hardware.
EC2 Architecture
- EC2 instances are virtual machines - meaning an Operating System plus an allocation of resources (virtual CPU, Memory, Storage etc.)
- EC2 instances run on EC2 Hosts - these are managed by AWS.
- These hosts are either shared or dedicated. Shared hosts mean you only pay for the instances you use on the host, other customers might also have instances on that host. Dedicated hosts you pay for the entire host and don't share it with anyone else.
- Hosts are AZ resilient they only run in one AZ.
- The Host is per AZ, the network is per AZ, the persistent storage (EBS) is per AZ --EC2 as a service is very reliant on the AZ the EC2s are in.
- You cannot connect EBS storage or Network Interfaces in one AZ to an EC2 instance located in another AZ.
EC2 Instance Types
- Instance types affect the amount of resources you get: CPU, Memory, Local Storage and Type of storage.
- Beyond the amounts they also have different ratios of resources eg. some types prioritize memory.
- Instance types also impact the amount of network bandwidth you get for storage and data networking capability.
- Instance types also impact the type of system architecture (ARM vs X86) etc.
EC2 Instance Type Categories
- General Purpose - The Default - built for a diverse workload they come with a fairly even resource ratio.
- Compute Optimized - Designed for media processing, HPC, Scientific Modelling, Gaming, Machine Learning.
- Memory Optimized - Designed for processing large in-memory datasets.
- Accelerated Computing - Used for specific niche requirements Hardware Dedicated GPU, FPGAs.
- Storage Optimized - Designed for Sequential and Random IO - scale-out transactional databases, data warehousing, elastic search etc.
Understanding Instance Type (Names)
Take for example: R5dn.8xlarge
The whole thing "R5dn.8xlarge" is known as the instance type.
The letter at the start in this case 'R' is the instance family.
The number after in this case '5' is the instance generation, in this case this is the 5th generation of the R family.
After the full-stop we have the instance size, in this case '8xlarge'.
In the middle of this example we have 'dn' this is not always present but it indicates special capabilities for the type. For example 'a' would indicate an AMD CPU.
EC2 Storage
Key Storage Terms:
- Direct (local) attached storage - For EC2 this is storage on the EC2 Host (called the instance store) - This suffers a few issues like if the disk fails the data is lost, if the hardware fails the data is lost or if the instance is moved to another host the data is lost.
- Network Attached Storage - Volumes delivered over the network, for AWS EC2 this is called Elastic Block Store (EBS). This is highly resilient and is separate from the EC2 hardware.
- Ephemeral Storage - Temporary Storage that you can't rely on to be persistent (For example the direct attached storage of the EC2 Host)
- Persistent Storage - Permanent Storage that exists as its own thing - it will live on past the lifetime of the device to which it is attached - in this case the EC2 instance. An example of this is EBS.
- Block Storage - Volume presented to the OS as a collection of blocks - no structure provided (it is up to the OS to create a file system and mount it), it is mountable and bootable (OS can be stored on it and the EC2 can boot from it). Block Storage can either be physical (a disk) or logical and delivered over a network.
- File Storage - Presented as a file share, it is structured - it is mountable but not bootable.
- Object Storage - Collection of objects, flat structure (none), Not mountable or bootable an example of this in AWS is S3.
Storage Performance:
There are 3 main terms when it comes to discussing storage performance:
- IO (block) Size. IO (input output) is like read and write.
- Input Output Operations Per Second (IOPS).
- Throughput - generally expressed in MB/s.
- The possible Throughput that can be achieved is the IO multiplied by the IOPS.
Elastic Block Store (EBS)
- Instances see the block device and create a file system on the device using the storage.
- Storage is provisioned in one AZ - it is resilient within that AZ so there is some back up unless the entire AZ fails.
- An EBS Volume is attached to one EC2 instance or other service over a storage network. (It is possible to attach it to more than one for rare requirements)
- EBS Volumes should be thought of as attached to one instance at a time, they can be detached and reattached to another instance.
- EBS Volumes are persistent - if an instance stops or starts that Volume is maintained - if an instance moves to a new host the volume follows it.
- You can snapshot EBS volumes to S3 which automatically replicates the Volume in all AZs within the Volume's original region. This allows you to then use that snapshot in another AZ and even copy the snapshot to a different region should you need it.
- Billed based on GB-month.
EBS Volume Types
General Purpose SSD:
- GP2 is the first iteration of this.
- GP2 volumes can be as small as 1GB or as large as 16TB.
- GP2 data is constricted by IO credits, every volume starts at the maximum capacity of 5.4million IO credits of 16KB each.
- If you use some of these credits they are topped up at a rate of 100 per second no matter the volume size until the capacity of 5.4million.
- This means you can't run at an IOPS higher than 100 indefinitely or the volume will run out of IO credits.
- GP2 has limited IOPS depending on the size of the volume (minimum limit 100).
- GP2 can however burst up to 3000 IOPS.
- GP2 limited to max throughput of 250MB/s
- GP3 is the later iteration of GP2
- It removes the credit bucket architecture of GP2.
- Volumes can be 1GB to 1TB
- Every GP3 Volume starts with a standard 3,000 IOPS and can transfer 125MB/s.
- Can pay extra for up to 16,000 IOPS with a higher throughput of up to 1,000 MB/s.
- 20% cheaper than GP2.
Provisioned IOPS SSD:
- Currently two types available IO1 and IO2 with IO2 Block Express in beta.
- These types of EBS Volumes allow you to adjust the IOPS regardless of Volume size.
- There is a limit for how many IOPS can be provisioned: IO1 50 IOPS per GB of Volume size, IO2 500 IOPS per GB of Volume size, Block Express 1,000 IOPS per GB Volume size.
- IO1 and IO2 allow for up to 64,000 IOPS per volume and 1,000MB/s throughput.
- IO1 and IO2 Volume sizing is from 4GB to 16TB.
- IO2 Block Express allows for up to 256,000 IOPS per volume and 4,000MB/s throughput.
- IO2 Block Express Volume sizing is from 4GB to 64TB.
- If you opt for high IOPS then you need to make sure it is paired with an EC2 that is capable of also meeting that level of performance.
HDD Based Volume Types:
- These are slower so you would only want to use them in specific situations.
- There are two types st1 (Throughput Optimized) sc1 (Cold HDD)
- st1 is cheaper than SSD and sc1 is cheaper than st1.
- st1 is useful for where cost is a concern but you need high throughput and frequent access eg. Big Data, data warehouses, log processing.
- sc1 is designed for infrequent workloads - where you want to store lots of data and don't care about performance. This is the lowest cost EBS type.
- Neither sc1 or st1 can be used to boot EC2 Instances.
Instance Store Volumes
- Physically connected to ONE EC2 Host.
- These provide Block Storage Devices.
- Instances on the host can access these volumes.
- Highest storage performance in AWS as they are already on the host.
- Included in the instance price.
- These are attached at launch and can't be attached after. The number you can have is limited by the EC2 type but you don't have to use/attach them.
- If an instance moves between hosts then any data that was on an instance store volume is lost. This happens quite often for example when you restart an instance.
Instance Store vs EBS
- If you need persistent storage you should use EBS and not Instance Store.
- If you require resilience use EBS as it is resilient within its AZ and can be backed up to S3.
- If you need storage which is isolated from instance lifecycles (on - off - reboot - delete - migrate - detach/reattach) use EBS.
- If you need resilience but your App has built in replication then it depends - you could use Instance Store Volumes across lots of instances without the negative risk.
- If you have high performance needs - it depends. Both can provide high performance but if you need super high performance you'll need to use Instance Store.
- Cost - Instance Store wins as it is normally included in the cost of the instance itself.
SAA Exam EBS & Instance Store Tips:
- A question that includes cost as a primary driver but requires EBS as an answer, you should use ST1 or SC1 - these HDD EBS options are cheapest.
- A question that mentions a requirement for high throughput you will want to use ST1 which is throughput optimized.
- If the question mentions Boot Volumes it can't be ST1 or SC1 as you can't use the mechanical EBS options to boot EC2 Instances.
- GP2/3 can deliver up to 16,000 IOPS per volume.
- IO1 and IO2 can deliver up to 64,000 IOPS per volume (*IO2 Block Express can deliver up to 256,000).
- Even with lots of combined EBS Volumes the maximum performance you can achieve per Instance is 260,000 IOPS (limited by Instance capabilities).
- If you need more than 260,000 IOPS and your Application can handle storage that isn't persistent then you can use Instance Store Volumes to provide this.
EBS Snapshots
- These are backups of EBS Volumes that are stored on S3.
- Snapshots are incremental - the first snapshot will be all of the data on the Volume - If you have a 40GB Volume with 10GB used the first snapshot will be 10GB in size - Future snapshots only store the difference between the previous snapshot and the state of the volume when that snapshot was taken.
- If you delete an incremental snapshot - AWS moves your data so all the snapshots after that point still function.
- EBS Volumes by themselves are only AZ resilient - by using S3 Snapshots the EBS Volumes become Region Resilient.
- Snapshots allow you to move EBS Volumes between AZs and even Regions.
- Restoring a snapshot is slower than creating a new Volume - unless you use Fast Snapshot Restore.
- Snapshots are billed at GB/month - only billed for used data not allocated data (eg. you've used 10GB of a 40GB volume).
EBS Encryption
- By default no encryption is applied to EBS Volumes.
- Even if you don't have EBS encryption applied the OS of the instance still could be performing disk encryption internally.
- EBS Encryption uses KMS using either a Customer Master Key (CMK) or a Customer Managed Key.
SAA Exam EBS Encryption Tips:
- Accounts can be configured to encrypt EBS Volumes by default - using a default CMK you set. Or you can also choose the CMK each time a volume is created.
- Each Volume uses 1 unique DEK. This DEK is only used for that volume and any snapshots of that volume you take in future also use that DEK.
- You can't change a volume from Encrypted to Non-Encrypted.
- EBS Encryption uses AES-256
- The OS isn't aware of the EBS Volume encryption
- If a question states you need to use a different encryption to AES-256 or you need the OS to encrypt the data. Then you need to use full disk encryption. You can use full disk encryption with either an unencrypted or encrypted EBS Volume as it is a different form of encryption.
- EBS Encryption has very little performance loss where as OS Full Disk Encryption has a cost to the CPU.
EC2: Network Interfaces & IPs
Every EC2 instance has at least one Elastic Network Interface (the Primary ENI) it can also have more than one ENI attached. When you interact with an instance through the console or within the network most of the time you are actually interacting with an Elastic Network Interface.
Lots of things you think are attached to the instance itself are actually attached to an ENI for example an Elastic Network Interface can/does have attached:
- Security Groups
- Mac Address
- Primary IPv4 Private Address (from the subnet range the EC2 is created in)
- 0 or more secondary Private IPs associated with the ENI
- 0 or 1 public addresses associated with the ENI
- Can have 1 elastic IP address per private IPv4 address
- 0 or more IPv6 addresses
- Can have Source/Destination check enabled. Traffic is discarded by the ENI based on these checks.
Elastic IP Addresses are allocated to your AWS Account - when you allocate an EIP you can associate it with a private IP either on the primary interface or a secondary interface. If you associate it with a primary interface that already has a normal public IP (non-elastic) that normal public IP is removed and the EIP becomes the new public IP address. If you then removed the EIP there is no way to get back that original normal IP address (it does get a new one but it's completely different).
EC2 Networking Solution Architect Exam Tips:
- A Secondary ENI with its own MAC address is really useful for licensing. Secondary ENIs can be detached and reattached to other EC2s. This means if you sign up for a license using a Secondary ENI and its MAC address you could then move that license between instances.
- Each ENI needs its own Security Groups as they are attached to Network Interfaces themselves.
- The OS never sees the IPv4 Public Address - this is a service provided by NAT. You always configure the Private IPv4 address inside the OS.
- Non-Elastic Public IPs are dynamic- stopping and starting the instance changes this IP.
- The Public DNS resolves to the primary private IP address in the VPC, resolves to the public IP elsewhere. So that if you use the Public DNS Name within the VPC it doesn't have to go to the internet gateway to figure out where to send the data within the VPC itself.
Amazon Machine Images (AMI)
AMIs can be used to launch EC2 instances, for example you can select the AWS Ubuntu AMI to launch an EC2 and the EC2 will be created with the Ubuntu OS already configured on it. AMIs can be provided by AWS or by the Community. For example RedHat provide their own Community AMIs. There are also Marketplace AMIs which you can purchase if you need an AMI for a niche purpose and don't want to configure the machine yourself - these AMIs can include commercial software installed as well.
- AMIs are regional - they have unique IDs but the same AMI eg. AWS Ubuntu 16.04 LTS will have a different ID in each region. An AMI can only be used in the region it is in.
- When you create an AMI it is automatically set to only be usable by Your Account, however you can adjust this permission to make the AMI public or for use by specific accounts.
- You can create an AMI from an EC2 instance you want to template.
- When you create an AMI from an existing EC2, snapshots of that EC2's EBS Volumes are taken and those snapshots are referenced by the AMI when you use it to create another instance. This mean the new instance will have the same EBS volume configuration as the original.
AMI SAA Exam Tips:
- AMIs only work in one region - even AMIs you create yourself will only work in the region it is created in - but an AMI can be used to deploy in all AZs.
- AMI Baking is the concept of launching an EC2 Instance installing all of the software & doing all of the configuration changes and then baking that into an AMI which can be used over and over again.
- An AMI cannot be edited - to change an AMI you should use it to launch a new instance, update the configuration on that instance and then use that to make a brand new AMI.
- AMI's can be copied between regions.
- Permissions for AMIs default to AMIs only being able to be accessed by your account. The two other permissions available are fully public and specified accounts.
- AMI costs come from the fact they contain EBS snapshots so you are billed for the capacity used by those snapshots.
EC2 Purchase Options
On Demand is the default purchase option:
- On Demand instances are isolated but multiple AWS Customer instances run on the same shared hardware with this option.
- It uses Per-second billing while the instance is running. If the instance is not running you are charged for the computing cost of the instance. However resources such as storage which use capacity whether the instance is running or not will still incur a charge.
- You should always consider On Demand for all projects and only move to another option if you can justify it.
- There are no interruptions with On Demand - except for AWS failures the instance will run until you decide otherwise.
- You reserve no capacity with On Demand - if there are capacity restrictions (due to a major AWS failure) the reserved capacity receives highest access priority. So you should consider reserved capacity for business critical applications.
- On Demand has very predictable pricing - it is defined before hand and you pay for what you use. There are no specific discounts.
- It is suitable for Short term or unknown workloads.
- Especially suitable for short term or unknown workloads that cannot be interrupted.
Spot is the cheapest way to get access to EC2 capacity:
- Spot pricing is AWS selling unused EC2 host capacity for up to 90% discount - the spot price is based on the spare capacity at a given time - lower available spare capacity means a higher spot price.
- Spot pricing can go up depending on capacity so when purchasing spot capacity you set a maximum price you are willing to pay per second - this price you set can be more than the current price at the time you purchase for spot capacity.
- If the available spare capacity reduces to a point that the spot price is raised above the maximum price a customer has set then their instances are terminated to free up capacity.
- You should never use the Spot purchase options for workloads that can't tolerate interruptions.
- Good uses for the Spot purchase option are workloads which are not time critical. Any stateless, cost sensitive workloads which can be interrupted and started up again are good.
Standard Reserved Instances are for long term consistent usage of EC2:
- A reservation is where the customer has made a commitment to AWS for long term usage and payment for a set amount of EC2 resource.
- If you know you need an EC2 Instance for a long term consistent work load then it is often a good idea to purchase a reserved instance.
- The benefit of this is discounted instances: a reduction in per second pricing or maybe no per second pricing at all depending on what type of reservation you purchase.
- Unlike On Demand an unused reservation is still billed even if it is not used.
- You can lock a reservation to an Availability Zone or to a Region - if you limit it to a particular AZ you can only benefit from pricing discounts when launching instances in that AZ.
- If you do lock a reservation to an AZ it reserves capacity in the AZ for your reservation. Whereas locking a reservation to a region still gets you the benefits of pricing discounts for any Instances launched into any AZ in that region, but locking a reservation to a region does not reserve capacity for your reservation.
- Reservations can have a partial effect. If you have reserved space for a T3.Large EC2 Instance and then launched a T3.XLarge (which is a bigger Instance than you reserved) you would still receive beneficial pricing on the portion of resources you have reserved that make up the larger instance you have launched.
- There are two term options for reservations - you can either commit to a reservation for 1 year or 3 year terms - you pay upfront for the entire term. A 3 year term is cheaper than 1 year. A 3 year term full upfront payment is the cheapest option.
- You can also agree to a 1 or 3 year term with no upfront payment where you pay a reduced (from on demand) per second fee which you pay whether the Instance is running or not.
- It is also possible to have a partial upfront option - where you then receive a cheaper per/s fee.
Scheduled Reserved Instances:
- These are good for long term usage requirements but where the EC2 does not need to run constantly.
- For instance if you have batch processing that needs to run daily for 5 hours. A standard reserved instance would not work in this case as you don't need the instance to run 24/7. However you do know you need an EC2 to run this 5 hour process every day.
- This is where you can use a Scheduled Reserved Instance - you let AWS know the frequency, the duration and the time you need the EC2. Then you commit to paying for an EC2 during these specified periods for a set term.
- This will give you the requested capacity for a cheaper rate than on demand.
- You can schedule reserved instances - daily, weekly or monthly.
- Not all regions support scheduled reserved instances, 1200 hours per year must be scheduled and the minimum term is 1 year.
Dedicated Hosts are EC2 hosts allocated to a single customer in its entirety:
- In this option you pay for the host - any instances launched on that host have no per second charge.
- You can launch as many instances of any size on a dedicated host - up to the maximum capacity of the dedicated host. You could even launch one instance that uses all the resources of the host.
- Any unused capacity is wasted - but you still pay for it.
- This option is often used if you have application licenses that are reliant on Sockets and Cores.
- Dedicated Hosts have a feature called host affinity which links instances to certain EC2 Hosts. So if you stop and start an instance it will remain on the same EC2 Host.
Dedicated Instances are generally used for industries with strict security requirements:
- With Dedicated Instances you don't own or share the host - but any instances you launch are launched on an EC2 Host that only hosts instances belonging to you.
- You pay per instance and you don't pay for the host itself - but AWS commits to not host any other customer's instances on the same hardware your dedicate instances are on.
- For this you pay a higher rate for the instances and there is also an hourly fee per region you want to use dedicated instances in - you pay this same fee every hour no matter how many Dedicated Instances you have in the region.
- This is mostly used by customers who have strict requirements not to share hardware - but you don't have to manage the EC2 Host capacity itself.
EC2 Savings Plan: Customers make a commitment to spend a certain amount per hour on EC2 for a 1 - 3 year commitment. In exchange they receive a reduction in the amount they pay for resources. This applies to EC2, Fargate & Lambda.
Capacity Access in the event of failure:
In case of a failure resulting in not enough capacity vs demand AWS will assign capacity based on reservation. So for instance those customers that have reserved instances that are locked in to an AZ have capacity reserved for them in the AZ (doesn't apply if the reservation is locked to a region) - these customers will have capacity access priority in the event of failure.
However in the case that a customer cannot justify locking themselves into a 1 - 3 year term for a reserved instance there is still an option: On-Demand Capacity Reservations. These are reservations that ensure a customer always has access to capacity with in a specific AZ - but at full on-demand price. There are no term limits but customers pay regardless of whether they use the capacity.
EC2 Instance Status Checks:
EC2 has two high level per instance status checks.

These checks are performed every time an instance is started up and each check represents a separate set of tests. The first status check is the "system status" this check is focussed on issues affecting the EC2 service or the EC2 Host. The second check is the "instance status" a failure of this check could indicate a corrupted file system, incorrect instance networking or OS kernel issues. Anything but 2/2 checks represents a problem that needs to be solved.
Horizontal and Vertical Scaling
Scaling is used when your EC2 instance is out of useable resource for the task/s it is required to do. There are two types of scaling:
Vertical Scaling:
- This refers to increasing the size of the EC2 instance itself to cope with the demand for resource.
- There are cons to this:
- Each resize will require a reboot which causes disruption. This means typically you can only resize during set maintenance windows where this disruption won't cause issues. This limits how quickly you can respond to scaling need.
- Larger instances also often carry a price premium (in a non linear way) so scaling up is not always cost effective.
- There is an upper cap on instance size - there is a limit to how large an EC2 can get.
- There are also benefits:
- Vertical scaling requires no application modification. You are simply running the application on a larger instance.
- It works for all applications - even monoliths.
Horizontal Scaling:
- This refers to increasing the number of instances to cope with demand for resource.
- This architecture will have multiple copies of an application running across smaller compute instances. These all need to take their share of demand placed on the system by customers. This generally means using a load balancer to distribute load/demand across all the instances.
- When thinking about Horizontal Scaling - sessions are everything. Due to this Horizontal Scaling requires Application Support OR off-host sessions (where sessions are externally hosted somewhere else).
- There are quite a few benefits to Horizontal Scaling:
- No disruption when scaling.
- No limits to scaling as you can just keep adding instances.
- It's often cheaper than vertical scaling as you are using smaller instances which don't have a dollar premium.
- It's more granular in the amount of capacity you can add. Eg. if you have 5 instances running and add one more you are only adding 20% to the capacity.
Scaling Solutions Architect Exam Tips:
- Horizontal Scaling add or removes instances.
- There is no limit to Horizontal Scaling.
- Vertical Scaling increases the size of the instances themselves.
- Vertical Scaling is limited to the largest instance size offered by AWS.
Containers and ECS
Container Basics
As has already been discussed EC2s are virtual machines. Each EC2 is a virtualised system with its own OS residing on an EC2 Host machine. One issue with this is that the OS on these virtual machines can actually consume a large amount of the resource allocated to the virtual machine.
This means you might have 4 Applications running in 4 different virtual machines all with their own operating systems consuming a lot of resources. However if all of those virtual machines use the same Operating System (pretty common they may all be on the same Linux Distro) then a better answer would be for all of the 4 Apps to run on a shared OS to save resources. However in doing this we would still want them to be logically isolated. Enter Containerisation.
A container in some ways is similar to a virtual machine in that it provides an isolated environment which an application can run within. However, where VMs run as a whole isolated Operating System a Container runs as a process within the host Operating System. The container is isolated from all the other processes but can use the Operating System for a lot of things like networking and file I/O.
By far the most popular tool for containerisation is Docker:
- Dockerfiles are used to build images and these images are used to run containers.
- Containers are portable - self contained and they always run as expected - as long as they are on a compatible host.
- Containers are light weight - they use the host OS for heavy lifting.
- Containers only run the application and the environment it needs - they use very little memory and are fast to start and stop.
- They provide most of the isolation that VMs do.
Elastic Container Service (ECS) Concepts
AWS ECS takes away a lot of the over head of self managing your container hosts as it provides the infrastructure for you to run your containers on. ECS is a managed container based compute service - it runs in two modes: EC2 & Fargate (Serverless).
ECS lets you create a cluster - these are where your containers run from. AWS also has it's own container registry called Elastic Container Registry (ECR) this provides a similar function to Docker Hub, storing your container images for use running containers down the line.
Once you have an ECS cluster you need to create a "Container Definition" this lets ECS know where the image you want to run as a container is as well as which port(s) your container uses.
You also need to create Task Definitions within ECS. These Task Definitions represent an application - a single Task Definition might contain one container or many depending on the complexity of the application eg. a Web App container and a Database container. Task Definitions also store the resources used by the Task (CPU & Memory), they store the networking mode that the task uses and they store the compatibility (whether it runs in EC2 Mode or Fargate).
One really important thing the Task Definition stores is the Task Role. The Task Role is an IAM Role that a task can assume to give it temporary credentials to interact with other AWS products and services.
An ECS Service Definition defines how we want a Task to scale - it can add capacity and add resilience. With an ECS Service you can run multiple instances of tasks concurrently with a load balancer in front of them for example.
ECS Cluster Types
There are two Cluster Types: EC2 and Fargate (Serverless) - One of the main differentiators between these two modes is what part the customer is responsible for managing and what parts AWS is responsible for managing.
In both modes ECS manages Scheduling, Orchestration and Container Placement.
EC2 Mode:
- With this mode an ECS Cluster is created within a VPC in your AWS Account.
- As it runs within the VPC is benefits from the multiple Availability Zones within the VPC.
- In this mode EC2 Instances are used to run the containers. When you create the cluster you specify an initial size which controls then number of container instances - this is handled by an auto scaling group (for ASG info see section below on HA & Scaling).
- The auto scaling group controls horizontal scaling for EC2 instances - adding more when requirements dictate and removing them when they're not needed.
- Via Task Definitions and Services, images are deployed onto the EC2 Instances in the form of containers.
- In EC2 Mode, ECS will handle the number of tasks that are deployed if you utilise Services and Services definition.
- However you need to manage the capacity of the cluster itself as the container hosts are not something delivered as a managed service - they are just EC2 instances.
- You are expected to manage the number of container hosts inside a cluster and you will pay for unused running capacity.
Fargate Mode:
- You don't have to manage EC2 hosts for use as container hosts.
- You have no servers to manage. It is considered Serverless - there are still servers running your containers but they are managed by AWS.
- Fargate is a pool of shared compute resources - when your container is running on Fargate your Task and Service definitions are running on this shared infrastructure. You interact with it via a network interface that is injected into one of your VPCs.
- As the infrastructure is all shared you only pay for the capacity that your containers actually use.
SAA Exam Tips: ECS-EC2 vs ECS Fargate:
- If a customer uses containers already pick an ECS option rather than running their Application on a standard EC2 Instance.
- Pick ECS EC2 Mode if you have a large workload and are price conscious.
- Pick ECS Fargate if you are wary of large management overhead - even for large workloads.
- Pick ECS Fargate for small and burst workloads as you only pay for what you use.
- Pick ECS Fargate for batch or periodic workload as you only pay for what you use.
EC2: Advanced Knowledge
Bootstrapping EC2 with User Data
Bootstrapping allows us to automate configuration of EC2s upon deployment (launch) eg. running scripts and software installations. This is a different process to creating an AMI and building the EC2 from it with everything preconfigured.
In order to Bootstrap an EC2 you have to pass "User Data" to the meta-data IP http://169.254.169.254/latest/user-data, anything in User Data is executed by the instance's OS as the root user. This only applies to the initial launch of the EC2 any subsequent restarts will not run the scripts or actions specified by the User Data. User Data is nothing to do with Users, it is data passed by you the User to the EC2s OS for configuration.
EC2 in no way validates what you pass in as User Data - only the OS needs to understand it. You could pass in actions that would delete all data on the boot volume and as EC2 does not validate or check it won't stop you.
- User Data is not secure - don't use it for credentials or passwords. Anyone who can access the Instance OS can access the User Data.
- User Data is limited to 16KB in size.
- User Data can be modified when the instance is stopped - but it is only executed once at launch not on restart so modifying it only serves to pass new data in, not execute it.
Bootstrapping can be done in more detail with CloudFormation Init. This is done with the cfn-init script which is installed on the EC2 OS. This cfn-init can be written procedurally (imperative do these actions, line by line) or it can specify a desired state.
EC2 Instance Roles
These are roles that EC2 Instances can assume and anything in the instance has the permissions that the role grants.
- They are constructed out of an IAM Role with a Permissions Policy Attached to it.
- Whatever EC2 assumes the role gets temporary credentials that give the permissions in the policy.
In order to deliver the permissions to the EC2 Instance an Instance Profile is required, this is a wrapper around an IAM Role and allows the permissions to get inside the instance. When you create an Instance Role in the console this Instance Profile is also created with the same name. However if you create the Role using CloudFormation (Or Terraform) then you need to create the profile separately.
- It is the Instance Profile and not the Role that is attached to the instance.
- Credentials are delivered by the meta data - these are always rotated and valid they do not need to be renewed.
AWS Systems Manager - Parameter Store
The Parameter Store is an AWS service that makes it easy to store various bits of system configuration eg. Strings, Documents and Secrets.
- Parameter Store offers the capability to store 3 different types of parameters: String, StringList and SecureString.
- Within the service you can store things like: license codes, database connection strings, full configs and passwords.
- You can store using a hierarchical structure (like folders/directories) and also offer versioning.
- Can store in plaintext and cyphertext (using KMS).
- Public Parameters - these are parameters provided by AWS eg. AMI IDs.
- It is a Public Service so anything using it needs to be an AWS Service or have access to the AWS public space endpoints.
- Parameter Store parameter changes can create Events.
These parameters can then be passed by the store into your Application or AWS Services like EC2 and Lambda.
System and Application Logging on EC2
Sometimes you will want to monitor and have access to information of the OS itself eg. looking at the processes running, their memory consumption, you might also want to provide AWS access to application and system logging happening within the EC2.
- CloudWatch and CloudWatch Logs don't natively capture data inside an instance.
- In order for them to be able to do this the CloudWatch Agent is required to be installed on the EC2.
- The agent captures the data you require and sends it to CloudWatch.
- You need to configure the agent to tell it what data you want it to pull from the instance. It will also need an IAM Role attached to the EC2 with permissions to access CloudWatch.
EC2 Placement Groups
Normally when you launch an EC2 Instance its physical location is selected by AWS - placing it on whatever EC2 Host makes the most sense within the AZ zone it is launched in. Placement Groups allow you to influence the physical location your EC2s are launched in allowing you for example to ensure your EC2s are all physically close together.
There are 3 types of Placement Groups:
- Cluster - Pack instances physically close together.
- Spread - Keep instances separated - they all use different underlying hardware.
- Partition - Groups of Instances but each group is on different hardware.
Cluster:
- Used when you want to achieve the absolute highest possible level of performance available within EC2.
- Typically you would launch all of the instances you'll want in the cluster at the same time so AWS allocates enough capacity on the hardware.
- Best practice is to use the same type of EC2 for all of the instances & not all instance types are supported.
- They are all placed in the same AZ.
- All Instances in the cluster group have direct connection to each other.
- This gives them single stream transfer rates of 10Gbps vs 5Gbps normally.
- This provides lowest latency and maximum packets per second available in AWS.
- A Cluster Placement group provides low resilience as all Instances are on the same host or rack.
Spread:
- Spread Placement Groups can span multiple AZs in a region.
- Every instance is placed on separate rack with its own network & power supply.
- Limited to 7 Instances in a group per AZ.
- Provides infrastructure isolation.
- You cannot use Dedicated Instances or Hosts.
Partition:
- Partition Placement Groups can be created across multiple AZs in a region.
- The group is divided into partitions, each partition has its own racks and no sharing of infrastructure between partitions.
- Each partition can contain as many Instances as you need.
- You can control which partition you are launching instances into.
- These are designed for huge scale parallel processing systems where you need to create grouping of instances and have them be separated.
- You can have maximum 7 Partitions per AZ .
- Instances can be placed in a specific partition or EC2 can do it automatically.
- Great for Topology Aware Applications using tools like HDFS, HBase and Cassandra.
- Contains the impact of failure to a part of the application.
EC2 Dedicated Hosts
- An EC2 Host which is dedicated to you.
- You pay for the entire host which is designed for a specific family of instances eg. a1, c5, m5 etc.
- No per instance charge as you are already paying for the entire host.
- You can pay for a host on-demand or as a reservation with a 1 or 3 year term.
- Host hardware has physical sockets and cores - good for licensing software which is based on sockets and cores.
- Most dedicated host options ask you to set the instance size in advance. This applies to the hosts that aren't nitro based.
- Dedicated Hosts can be shared with other accounts in your organisation.
Dedicated Hosts Limitations:
- AMI Limits - You cannot use RHEL, SUSE Linux or Windows AMIs
- Amazon RDS Instances are not supported.
- You cannot use Placement Groups.
Enhanced Networking & EBS Optimised
Enhanced Networking:
- Needed for high performance optimised architecture like using Cluster Groups.
- Uses SR-IOV - The network interface card is virtualization aware.
- This allows for higher I/O & Lower Host CPU Usage.
- Results in more bandwidth and higher packets per second (PPS).
- Consistent Lower Latency.
- Enhanced Networking is either enabled by default or available for no charge on most EC2 Instance Types.
EBS Optimised Instances:
- EBS is block storage over the network.
- Historically the network was shared between data and EBS.
- EBS Optimised means there is dedicated network capacity for EBS.
- Most instances support this and enable it by default.
- Needed for low latency and high I/O & Throughput.
Route 53
Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It is designed to give developers and businesses an extremely reliable and cost effective way to route end users to Internet applications by translating names like www.example.com into the numeric IP addresses like 192.0.2.1 that computers use to connect to each other. Amazon Route 53 is fully compliant with IPv6 as well.
Amazon Route 53 effectively connects user requests to infrastructure running in AWS – such as Amazon EC2 instances, Elastic Load Balancing load balancers, or Amazon S3 buckets – and can also be used to route users to infrastructure outside of AWS.
Route 53 Hosted Zones
- A R53 Hosted Zone is a DNS Database for a domain.
- Route 53 is a Globally Resilient service with multiple DNS servers - so it can survive entire regions being down.
- Hosted Zones are created automatically when you register a domain using Route 53 - they can also be created separately if you register a domain elsewhere and want to use R53 to host it.
- A Zone hosts DNS records (eg. A, AAAA, MX, NS, TXT)
- Hosted Zones are what the DNS system references when trying to resolve a domain hosted on route 53.
- As long as a VPC has DNS enabled it can access Route 53 via the VPC +2 address which is the R53 resolver.

Public Hosted Zone:
- DNS Database (Zone file) hosted by R53 on Public Name Servers.
- These Zones are accessible from both the public internet and within VPCs.
- Hosted on 4 Route 53 Name Servers (NS) specific for the zone.
- There is a monthly cost for hosting the zone and a tiny charge for each query made against it.
Private Hosted Zones:
- Just like a Public Hosted Zone except it's only accessible within the VPCs it is associated with.
- It is inaccessible from the public internet.
- A Private Hosted Zone can also be accessible from a different accounts VPC with some config.
- You can use Split View where you have a Public and Private Hosted Zone for the same name. So the same Domain Name resolves differently dependent on whether it is being used internally or externally.
Route 53 CNAME vs ALIAS
- In DNS an A record maps a Name to an IP Address eg. name-example.com => 3.3.3.3
- CNAME maps a NAME to another NAME for example if you have name-example.com pointed to 3.3.3.3 you could create a CNAME record pointing www.name-example.com to name-example.com.
You can't use a CNAME record for a naked/apex domain (name-example.com). This creates an issue because many AWS services like Elastic Load Balancers (ELB) use DNS Names and not IPs - so you couldn't point name-example.com at an ELB as it would be invalid. You could however point a normal record like www.name-example.com at an ELB.
In order to point a naked/apex domain at another name you can use ALIAS record. Generally ALIAS records map a Name to an AWS Resource - they can be used for naked domains or for normal records. There is no charge for ALIAS record requests pointing at AWS Resources. For AWS Services - default to picking ALIAS.
Route 53 Simple Routing
- Simple Routing supports one record per name - but each record can have multiple values (multiple IPs).
- Use it when you want to route requests towards one service such as a web server.
- There are no health checks - all values are returned for a record when queried.
Route 53 Health Checks
Route 53 health checks monitor the health and performance of web applications, web servers, and other resources.
- Health Checks are separate from but are used by records within Route 53. They are configured separately from records.
- They are performed by a fleet of health checkers located globally.
- You can check anything accessible over the public internet it just needs an IP. It is not limited to AWS resources.
- Health Checkers check every 30s (every 10s costs extra).
- Checks can be TCP, HTTP/HTTPS, HTTP/HTTPS with string matching.
- Checks can be one of three types: Endpoint, CloudWatch Alarms, Checks of Checks (Calculated).
Route 53 Failover Routing
With Failover Routing you can add multiple records of the same name - A Primary and a Secondary. This means you can route to a different destination if your application has a failure. For example your Primary Record points to an EC2 based Web App, if that Web App fails your Secondary Record routes to a backup web server. Providing a very simplistic form of high availability.
This necessitates using a health check to see if the Primary Record is still routing to an available resource or if it has failed. If the Primary Record is healthy the route of the primary record is used - if it fails its health check the Secondary Record is used instead.
Multi Value Routing
This is similar to a mixture between Simple and Failover Routing. It allows you to create many records all with the same name that all map to different IP Addresses. Each record is independent and can have an associated health check. Any records which fail health checks won't be returned when the Hosted Zone is queried. Up to 8 healthy records are returned if more exist 8 are randomly selected.
Used when you have many resources which can all service requests- eg. many web servers for your Web App.
Weighted Routing
This can be used when you're looking for a very simple version of load balancing or testing new software versions. You can have a Hosted Zone with a number of records, for example 3 all pointing to different IP Addresses (in this case 3 web servers). You can assign each of these Records a weight eg. 40, 40 & 20 - these numbers then correlate to the amount of the times these records are returned upon query. Weights don't need to add up to 100, Records are simply returned based on their assigned weighting vs the total weighting.
You can use health checks in conjunction with Weighted Routing - when a record is selected, if that record is unhealthy the process of selecting a record based on the weighting is repeated until a healthy record is found. However these health checks don't affect the weighting calculation - if one record is found to be unhealthy its weighting is still used even though it is skipped in selection.
Latency-Based Routing
This should be used when trying to optimise for performance and user experience. With this you have multiple records under the same name and each record is assigned an AWS Region - the idea being you assign a region based on where the infrastructure for that record is. AWS then knows users rough location based on IPs and returns the record that will give them the lowest latency.
This can be combined with Health Checks, if a record is unhealthy the next lowest latency is returned.
Geolocation Routing
In many ways this is similar to Latency Routing. When you create records you tag them with a location - this is either a subdivision (US State), country, continent or default. When a user makes a request, their IP is checked for location and then Geolocation Routing will return the most specific record - eg. Is there a record tagged for their country, no, how about their continent, no, okay return default record.
You do not have to specify a default record - if there is no default and no records match for a user it will return "No Answer".
This does not return the closest record - merely the one that is relevant. If a user is in Argentina and there is a record for Brazil it will not return the Brazil record even though it may be closer than the default record.
This is ideal if you want to restrict content by geography. Also for language specific content.
Geoproximity Routing
This aims to provide records which are as close to customers as possible. Where Latency-based routing works on the lowest latency from customer to a record, Geoproximity Routing provides records which are the least distance from a customer.
With Geoproximity you define a region for AWS resource records or a latitude longitude for non-AWS resource records.
Geoproximity also allows you to specify a bias, a plus or minus which increases or decreases the regions effective size. This bias is taken into account when routing according to least distance - and can mean that the actual least distance isn't used because the bias dictates to use a resource slightly further away if connecting from certain locations.
With bias you can essentially say - the UK actually now extends to Russia and Spain, so Geoproximity will mean users connecting from North Africa for example will be routed to the UK rather than resources you might have in South Africa.
Route 53 Interoperability
- Route 53 acts as a domain registrar and it provides domain hosting.
- It can do both - which is what happens initially when you register a domain.
- Or it can be only a domain registrar or only a domain host.
In examples where R53 does Both:
- R53 accepts your money (domain registration fee).
- R53 allocates 4 Name Servers (NS) (R53 acting as a Domain Host).
- R53 creates a zone file (R53 acting as a Domain Host) on the above NS.
- R53 communicates with the registry of the TLD service for whatever domain you are using (.org, .com) and sets the NS records for the domain to point at the 4 NS above (R53 acting as a Domain Registrar)
Relational Database Service (RDS)
Database General Theory
Databases are broadly split into two model types: relational (SQL) and non relational databases (NoSQL). Relational databases are often thought of as SQL (Structured Query Language) databases. Another important acronym to know is RDBMS - relational database management systems which just refer to platforms on which you can run relational databases.
Relational Databases:
- Use SQL
- Have a structure in and between tables of data - this structure is known as a schema and the schema is either fixed or rigid.
- The schema defines things like tables names and type of values allowed within tables.
- There is a fixed relationship defined between tables.
- This fixed schema is hard to change once created and data is inputted and so makes it difficult to store data that has rapidly changing relationships.
For more info on how a relational database is structured and stores data this 5 minute video is very helpful: Relational Database Concepts.
No SQL:
- These databases are not one thing - rather any model that doesn't fit into the SQL mould - everything that isn't relational.
- Generally have a much more relaxed schema. It is either weak or there isn't one at all.
- Relationships between data are handled very differently.
Examples of NoSQL Databases:
Key-Value Databases:
- Consists of sets of keys and values.
- Generally there is no structure.
- As long as every single key is unique the value doesn't matter it can be anything, there is no schema and there are no tables or table relationships.
- They are really scalable as data relationships don't need to be taken into account you could spread the database across many servers.
- They are really fast.
Wide Column Store:
- DynamoDB is an AWS service which is this type of database.
- Uses tables, rows, and columns, but unlike a relational database, the names and format of the columns can vary from row to row in the same table.
- A wide-column store can be interpreted as a two-dimensional key–value store.
- The only rule is that the key used to identify the data within the database has to be unique.
Document Database:
- Data is stored in a document(s) - typically in JSON or XML.
- The structure can differ between documents.
Column Databases:
- Redshift is an example of this in AWS.
- While a relational database is optimised for storing rows of data, typically for transactional applications, a columnar database is optimised for fast retrieval of columns of data, typically in analytical applications.
- Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk.
Graph Databases:
- A graph database stores nodes and relationships instead of tables, or documents.
- Data is stored just like you might sketch ideas on a whiteboard.
- Your data is stored without restricting it to a pre-defined model, allowing a very flexible way of thinking about and using it.
- Can store a massive amount of complex relationships between data.
ACID vs BASE
- These are both Database transaction models.
- They are answers to the CAP Theorem that states within a Database you can only have two of Consistency, Availability and Partition Tolerance (Resilience).
- ACID focuses on Consistency and BASE on Availability - both provide resilience.
ACID stands for Atomic Consistent Isolated Durable
BASE stands for Basically Available Soft-State Eventually-Consistent - BASE does not enforce immediate consistency - any reads to a DB are eventually consistent. DBs that use BASE are highly performant and can scale consistently - Dynamo DB is an example of BASE. However Dynamo DB Transactions offers ACID functionality.
ACID / BASE SAA Exam Tips:
- Generally if you see ACID mentioned in an AWS Exam it is referring to any of the RDS databases. As RDS DBs are ACID based.
- If you see BASE mentioned in a question then you can safely assume it is referring to a NoSQL style DB.
- If you see NoSQL or Dynamo DB mentioned along with ACID then it may be referring to Dynamo DB Transactions.
Databases on EC2
This is arguably a bad practice in AWS - so at best implementing a database in this way requires some justification.
Why you might want to do it:
- If you need access to the DB Instance OS. As RDS and other services manage the OS for you.
- Advanced DB Option tuning (DBROOT)
- If you need to run a Database or DB Version that AWS don't support on any of its managed products.
- Specific OS/DB Combination AWS don't provide.
- A certain type of Architecture AWS don't provide.
Why you shouldn't:
- Admin overhead - managing EC2 and DBHost.
- Backup / DR Management is much more difficult.
- EC2 is single AZ.
- You don't have access to the really useful features of AWS' managed DB platforms.
- EC2 is ON or OFF - no serverless, no easy scaling.
- Replication is much more difficult.
- Performance - AWS invest a lot of time into optimisation of their DB products and features.
Relational Database Service (RDS) Overview
- RDS is a product which provides Managed Database Instances that can hold one or more databases.
- It supports most popular engines: MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server & Amazon Aurora.
- Offers massive benefits in terms of reduced admin overhead.
RDS Instances:
The most basic building block of RDS is the RDS Instance. An instance runs one of a few types of DB engines, it can contain multiple user created databases. You can access/connect to this database via its Database CNAME, a named endpoint that provides the only method of access (you can't use IPs).
In a similar way to EC2 Instances, RDS Instances come in various families, types and sizes eg. db.m5, db.r5, db.t3.
When you provision an instance you also allocate a set amount of storage - this is block storage attached to the instance and it exists in the same AZ as the RDS instance. This makes RDS vulnerable to a failure at an AZ level. This is why AWS provides a "Multi AZ" option.
Storage allocated to RDS Instances can be SSD (io1 or GP2) or it can be Magnetic, these have the same benefits as they do on EC2:
- GP2 - The default - great for burst pool architecture.
- io1 - Offers high end performance - lots of IOPS and low latency.
- Magnetic - More for compatibility in most cases these days.
RDS Billing: -
- You are billed for the RDS Instance itself based on the allocation of CPU and Memory.
- You are also billed for the amount of storage you allocate - similar to EC2 this is GB/m so 100GB for a month costs the same as 200GB for half a month.
RDS High Availability - Multi AZ
- Multi AZ is an option that is used to add resilience to RDS.
- When it is enabled secondary infrastructure is provisioned in another Availability Zone - this is referred to as the Standby Replica.
- The Standby Replica has its own storage in the same AZ the standby is located in.
- RDS enables synchronous replication from the Primary Instance to the Standby Replica.
- Synchronous replication means that when Writes happen on the Primary Instance they are immediately synced across to the Standby Replica - there is very little if any lag at all in data written between the two.
- In a Multi AZ system the DB CNAME Endpoint points at the Primary Instance by default - you cannot directly access the Standby Replica.
- If an Error occurs on the Primary Instance - AWS detects this and moves the CNAME Endpoint to point at the Standby Replica instead of the Primary Instance. This failover occurs within 60 - 120 seconds.
Multi AZ RDS - Exam Tips:
- Multi AZ is not available with the Free Tier - There is extra cost for it (generally it doubles the price).
- The Standby Replica can not be accessed directly - so it can not be used to scale the number of possible reads. It is an availability improvement not a performance one.
- A failover takes between 60 & 120 seconds.
- Multi AZ is in the same region only - it can only occur within other AZs within the same region as the Primary Instance.
- With Multi AZ back ups are taken from the Standby Replica - this does remove performance impact on the Primary Instance.
- Failovers can occur because of: An AZ Outage, Primary Instance Failure, Manual Failover, You change the primary instance type, during software patching.
- If you see Synchronous Replication you can assume it is talking about Multi AZ.
RDS Backups and Restores
Two important concepts to understand here are RPO (Recovery Point Objective) and RTO (Recovery Time Objective).
RPO represents the time between the last backup and a potential incident - therefore the maximum amount of data loss possible. A business will typically have an RPO target to meet - dictating how often backups need to be taken lower RPO means more often. Typically the lower this RPO value is the more expensive it is.
RTO is the time between the failure and when service is restored. This can be reduced through things like spare hardware and effective documentation. Again generally aiming for a lower RTO value makes the solution more expensive.
There are two types of backups in RDS:
- Automated Backups
- Manual Snapshots
Both types use s3 but are in AWS Managed Buckets and so aren't visible to customers within their own console. As backups are stored in s3 they are region resilient.
Manual Snapshots:
- For the first snapshot of a DB on RDS the snapshot is the full amount of used data. So if you have allocated 100GB but only used 10GB so far, the snapshot will be 10GB in size and the backup costs will reflect only storing 10GB not 100GB.
- Every snapshot after is incremental - so it only stores the changes made since the last snapshot was made.
- Manual snapshots exist forever unless you delete them - they exist beyond the lifespan of the RDS instance even if you delete it.
- Manual snapshots include all databases on an instance.
Automatic Backups:
- Snapshots that are done automatically in a scheduled window you define.
- First backup is full and the rest are incremental.
- Every 5 minutes DB Transaction logs are written to S3 - these are all the changes made on the DB. This means that in theory your RPO is 5 minutes as you can always restore to 5 minutes ago if something goes wrong.
- Automated Backups aren't retained indefinitely - you can set a retention period anywhere from 0 - 35 days.
- If you set the time to 35 days you could restore to any point in time in the past 35 days using the Snapshots + the transaction logs.
- When you delete the DB you can choose to keep the automated backups but they still expire according to their set retention period.
RDS Snapshots Solutions Architect Exam Tips:
- When you restore from a backup - AWS creates a new RDS Instance.
- When you restore a manual snapshot - you are restoring to single point in time (when the snapshot was created).
- Automated Backups give you the ability to restore to any 5 minute point in time.
- Restores aren't fast and can therefore affect RTO.
RDS Read-Replicas
Read-Replicas provide both performance benefits and availability benefits.
Unlike stand-by instances which you can't access or use for anything - you can use Read-Replicas but only for read operations. They have their own endpoint address and are kept in sync using asynchronous replication. When you see asynchronous in an RDS context think Read-Replica.
With Asynchronous Replication data is written fully to the primary instance first and then once it is stored on disk it is replicated to the Read-Replica(s). This can introduce a very small amount of lag.
Read-Replicas can be created in the same region as the primary database or they can be created in other AWS regions (Cross-Region Read-Replica).
Performance Improvements:
- You can have 5 direct Read-Replicas per DB Instance.
- Each of these provide an additional instance of read performance.
- Read-Replicas can have read-replicas but this starts to introduce lag problems.
- Can provide Global performance improvements by using a Read-Replica in multiple regions.
- Read-Replicas are Read only until promoted.
Availability Improvements:
- While Snapshots and Backups improve RPO they don't help RTO that much.
- Read-Replicas offer near 0 RPO and they can be promoted to Primary Instance quickly meaning they have low RTO.
- Read-Replicas are only helpful for availability in the event of Failures - if there is an issue caused by data corruption in the Primary Instance this will also exist in the Read-Replica.
- Cross Region Read-Replicas offer global resilience.
Read-Replicas are how you scale read loads on your DB - but you cannot use them to scale writes.
Read-Replica Solutions Architect Exam Pointers:
- When you see Asynchronous Replication think Read-Replicas.
- When you see Synchronous Replication think Multi AZ.
RDS Data Security
Encryption in Transit:
- With every engine in RDS you can use encryption in transit (SSL/TLS) - This can be set to mandatory on a per user basis.
- By default it is enabled using KMS.
- The data is encrypted by the Host the RDS instances EBS volumes are stored on - as far as the RDS knows it is writing unencrypted data to this storage.
- AWS or Customer Managed CMK generates the data keys used for the encryption operations.
- When using this Storage, Logs, Snapshots & Replicas are encrypted.
- In addition to KMS EBS based encryption Microsoft SQL and Oracle support TDE. This encryption is handled by the DB engine itself.
- Also Oracle supports integration with CloudHSM - much stronger key controls (more security).
IAM DB Auth:
It is possible to use IAM Authentication to login to RDS instances instead of Users and Password. However this is not authorization - it is only Authentication. Permissions for users actions are still defined in the DB itself.
Amazon Aurora Architecture
While Aurora is officially part of RDS it does act somewhat like its own product.
- Aurora Architecture is very different from standard RDS.
- It uses a "cluster" made up of a single primary instance and 0 or more replicas. These Aurora Replicas provide the benefits of both RDS Multi AZ and Read-Replicas.
- Aurora doesn't use local storage for the compute instances with in the cluster - it uses a shared cluster volume. This means faster provisioning and better performance.
- The max size of a Cluster Volume is 128TiB, it has 6 replicate volumes across multiple AZs - when data is written to the primary instance Aurora replicates it to all of these 6 storage nodes spread across the Availability Zones.
- Replication happens at the storage level - so no extra resources are consumed on the primary instance or the replicas during this replication.
- By default the Primary instance is the only instance able to write to the storage and it and the replicas can all read from the storage.
- Aurora will automatically detect failures in a disk volume that makes up storage in the cluster and immediately repair that area using replicated data from other volumes in the cluster.
- Storage in Aurora is therefore much more resilient than the other RDS database engines.
- With Aurora you can have up to 15 Replicas and any of them can be the target for failover. Failover will be much quicker due to the shared storage.
- Storage is all SSD based - high IOPs and Low latency.
- When an Aurora cluster is created storage is not specified - you are billed on what is used.
- As storage is for the cluster and not the instances - replicas can be added and removed without requiring storage provisioning.
- There are at least two endpoints the Cluster Endpoint - points at the Primary Instance. The Reader Endpoint points at all of the Read Replicas and automatically load balances read requests across them - making read scaling very simple.
Aurora Costs:
- No free tier option
- Beyond RDS singleAZ micro instance Aurora offers much better value.
- Compute is charged hourly, per second with a 10 minute minimum.
- Storage is GB-Month consumed plus an IO cost per request.
Backups:
- Work much the same as standard RDS.
- Restores create a new cluster.
- Backtrack can be used which allows in-place rewinds to a previous point in time.
- Fast clones make a new DB from an existing one MUCH faster than copying all the data.
Aurora Serverless
- Provides a version of Aurora where you don't need to statically provision DB instances of a certain size or manage them.
- It removes the admin overhead of managing individual database instances.
- Aurora Serverless uses the concept of ACUs - Aurora Capacity Units. These represent a certain amount of compute and memory.
- When you create an Aurora Serverless Cluster you specify a minimum and a maximum ACU - in operation it will scale between these values.
- Cluster adjusts capacity based on load.
- Can even go to 0 and be paused.
- Consumption billing happens on a per-second basis.
- Same storage resilience as Aurora Provisioned (6 storage copies across AZs).
An Aurora Serverless Cluster has the same cluster storage structure as Aurora Provisioned but instead of instances we have ACUs which are allocated from a warm pool of Servers that are managed by AWS.
Scaling happens smoothly without causing any interruptions to applications that rely on the DBs.
Aurora Global Database
This allows customers to create global level replication from one master region to up to 5 secondary AWS regions. This is great for cross-region disaster recovery. Additionally it is very helpful for global read scaling - enabling low latency all over the world.
- 1 second or less replication between regions.
- Secondary regions can have 16 replicas each.
- Still only one primary instance in the master region - all replicas in the master region and secondary regions are read only.
Aurora Multi-Master
This feature allows an Aurora Cluster to have multiple instances which are capable of both reads and writes. The default Aurora mode is Single-Master which is one primary instance capable of reads and writes and zero or more Read-Only Replicas.
- In Multi-Master mode - all instances are Read / Write.
- When one DB Instance receives a write request it immediately proposes the data be written to all of the storage nodes in the cluster.
- This proposal can be rejected or accepted by nodes based on data that is already in flight (having been written to a different Instance).
- Whether data is accepted or rejected is based on whether a quorum of nodes will accept the data - if most accept but one rejects then the node rejecting will be overruled and the data will be replicated across all storage nodes.
- If a write is rejected it will generate an error in the application.
- Once data is accepted and replicated to the storage volumes - the data is also the replicated to the other instances themselves into their in memory caches.
Database Migration Service (DMS)
- A managed database migration service.
- A customer provides a source and a target database running on a variety of compatible engines.
- At least one of the source or target must be running on AWS.
- In between these two AWS will position a replication instance - an EC2 instance with migration software and the capability to communicate with the DMS service.
- On this replication instance you can define replication tasks - tasks define all of the options related to the migration.
- These tasks use provided source and destination endpoints to move data from the source db to the target db.
Migration Jobs can be one of 3 types:
- Full load - one off migration of all data (good if you can afford the downtime this will require)
- Full load + Change Data Capture (CDC) - Performs a full load migration while also copying across any ongoing changes in the source DB that happen during the migration (So minimal downtime needed).
- CDC only - If you want to use an alternative tool to do the Full load and then apply the ongoing changes after.
DMS also provides a tool called the Schema Conversion Tool (SCT) which can assist with Schema Conversion when migrating databases.
- SCT is only used when converting from one database engine to another OR for extremely large migrations (where you use Snowball).
- It is not used when migrating between compatible DB engines (engines of the same type).
When using DMS for larger migrations - multi TB in size it can often not be optimal to transfer the data over networks.
- Due to this DMS can use Snowball for bulk transfers of data into and out of AWS.
- If you were using this method to migrate from on-prem to AWS:
- This uses SCT to extract data locally and move it to a Snowball device.
- This snowball device is then shipped to AWS and they load it into an S3 bucket.
- DMS migrates from S3 into the target store.
- You can also use CDC in the time this takes to capture changes so they can be applied once the bulk migration is done.
Network Storage
Elastic File System Architecture
- EFS is an AWS implementation of NFSv4.
- With EFS you create Filesystems and these can be mounted within EC2 Linux instances.
- A single EFS Filesystem can be mounted on many EC2 Instances (Like a shared file system for EC2s).
- EFS storage exists separately from EC2 instances just like EBS is.
- EFS is a private service existing in the VPC it is attached to.
EFS uses the Mount Targets within Subnets of a VPC to provide EC2 instances access to the file systems. Each mount target has its own private IP address - taken from the range of the subnet it is in and this IP address is how EC2 Instances communicate with the Mount Target. For high availability it is suggested that each AZ has it's own Mount Target.

Even though EFS is a private service you can connect to an EFS Filesystem from on-premise through the use of a VPN into the VPC to directly connect to the Mount Target itself.
Elastic File System (EFS) AWS SAA Exam Tips:
- EFS is Linux Only.
- It offers two performance modes:
- General Purpose (The Default for 99% uses)
- Max I/O (High Throughput but comes with latency cost).
- Offers two throughput modes:
- Bursting - default choice (Works like GP2 in EBS - Throughput scales with size of File System) .
- Provisioned (Can specify throughput requirements separate from size).
- EFS offers two storage classes Standard and IA (infrequent access) - IA is cheaper.
Need help with when to use EBS and EFS - try this article.
High Availability and Scaling
Elastic Load Balancer (ELB)
Load Balancer Types:
There are currently 3 types of ELB available in AWS currently:
- These are split between V1 which you shouldn't use for any new projects and V2 which you should look to use.
- V1 Load Balancers:
- The only V1 load balancer is the Classic Load Balancer (CLB) - introduced in 2009 (it was the first load balancer on AWS).
- A big limitation is that they only support 1 SSL certificate per CLB.
- V2 Load Balancers:
- The Application Load Balancer (ALB) - Support HTTP/S & WebSocket - The Load Balancer you would use for any application using these protocols.
- The Network Load Balancer (NLB) - Supports TCP, TLS & UDP - For use for Applications that don't use HTTP or HTTPS. eg. Load Balancing email servers or SSH servers.
- V2 Load Balancers are faster, cheaper and support target groups and rules.
Elastic Load Balancer Architecture
When you provision a load balancer you have to decide on a few configurations:
- Whether to use IPv4 only or Dual Stack (IPv4 +IPv6).
- Which Availability Zones the Load Balancer will use - specifically you pick a subnet in two or more availability zones.
- The ELB will place one or more load balancer nodes into these subnets.
- When the ELB is created it is configured with a single (A) DNS record that points at all of the ELB Nodes - requests to that record are therefore distributed equally across all nodes.
- These nodes are Highly Available - if one node fails it is replaced, if requests increase then more nodes can be provisioned.
- Whether the Load Balancer should be internet facing or internal.
- Internet Facing ELBs have both public and private IP addresses - internal only have private addresses.
- Internet Facings ELBs can access both public and private EC2 instances.
Load Balancer nodes are configured with listeners which accept traffic on a certain port and protocol and communicate with targets on a certain port and protocol.
In order to function Load Balancers require a minimum of 8 IPs free per subnet they are provisioned in.
Cross Zone Load Balancing: This allows every node load balancer node to distribute requests across all registered instances in all AZs (rather then only distributing across instances in the same AZ as the node).
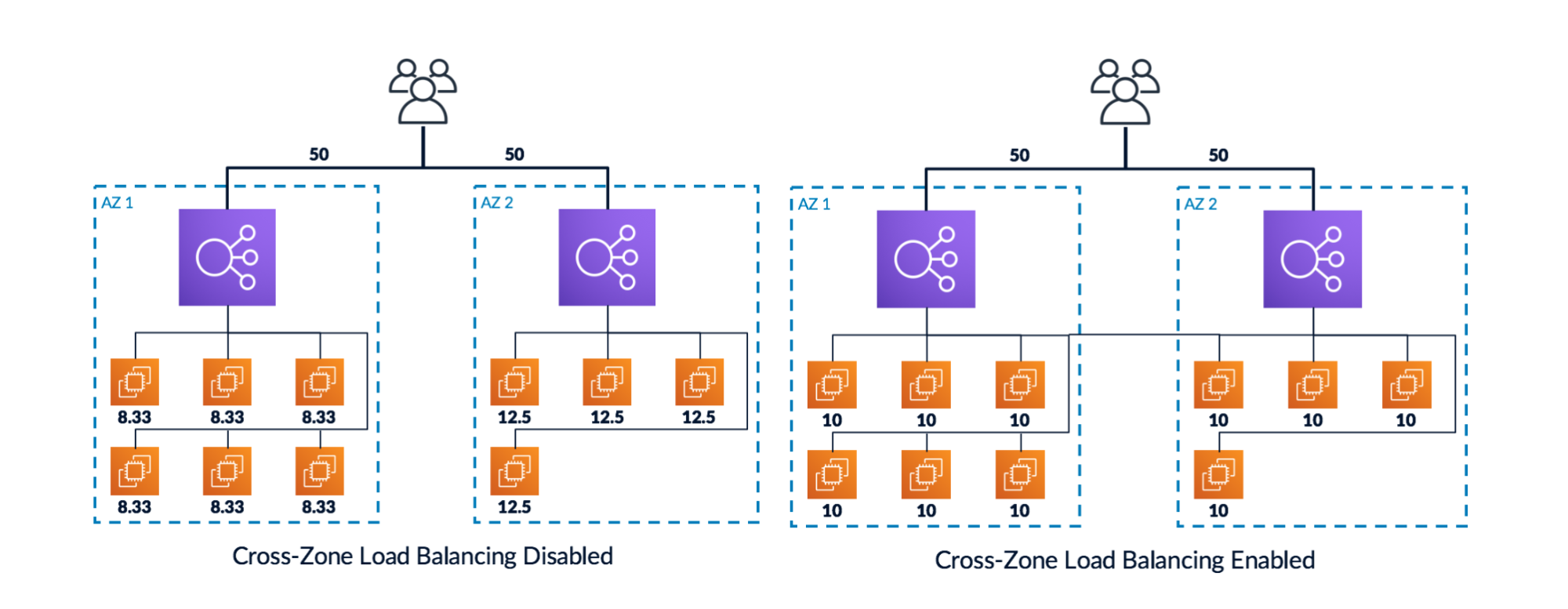
You can see how with Cross Zone Load Balancing enabled in the above image instances go from handling 8.33% or 12.5% of requests, to all instances sharing an equal 10% of requests.
Elastic Load Balancer Architecture - Solutions Architect Exam Tips:
- ELB is a DNS A record pointing at 1+ Nodes per (assigned) AZ.
- Nodes are placed in one subnet per AZ and can scale to more than one nodes per subnet if load increases.
- Internet Facing means nodes have public IPv4 IPs and Private IPs.
- Internet Facing Load Balancers can communicate with both Private and Public EC2s.
- An EC2 doesn't need to be public to use an internet facing load balancer.
- Require 8+ Free IPs per subnet - AWS recommend a minimum of /27 subnet to allow scaling.
Application Load Balancers vs Network Load Balancers
Application Load Balancer (ALB):
- ALB is a Layer 7 Load Balancer that only listens on HTTP and or HTTPS.
- ALB can't understand any other Layer 7 protocols eg. SMTP, SSH, special gaming protocols etc.
- It has to listen using HTTP or HTTPS listeners it cannot be configured to use TCP/UDP or TLS listeners.
- As it is a Layer 7 load balancer it can understand Layer 7 content: content type, cookies, custom headers, user location and app behaviour - it can make decisions based on this info.
- ALBs terminate HTTP/S connections and make a new connection to the application themselves - this means you cannot have an unbroken SSL encryption from server to client.
- ALBs must have SSL certs if HTTPS is used.
- ALBs are slower than NLBs as there are more levels of the network stack to process.
- ALBs can perform health checks at Layer 7 on the application.
ALB Rules:
- Rules direct connections which arrive at a listener.
- Rules are processed in priority order - the last rule processed is the 'Default Rule' which acts as a catch all.
- Rules can have conditions based on things like: headers, request method, query-string, source IP etc.
- Rules have actions based on this that will: forward, redirect, provide a fixed response or certain types of authentication.
Network Load Balancers (NLB):
- NLBs function at Layer 4 meaning they can interpret TCP, TLS, UDP, TCP_UDP.
- No visibility or understanding of HTTP or HTTPS.
- Can't understand headers, cookies or session stickiness.
- Really fast - can handle million of requests per second with 25% of ALB Latency.
- Good for SMTP, SSH, Game Servers (not using http/s), financial apps.
- NLB health checks only check ICMP and TCP handshaking - it is not app aware.
- NLBs can have static IP's which is useful for whitelisting - eg. a client needs to whitelist your NLB IP.
- Can forward TCP to instances with unbroken encryption (including any levels built on top of TCP).
ALB vs NLB - Tips for SAA Exam.
- If you need to perform unbroken encryption between a client and your instances use NLB.
- If you need Static IP for whitelisting use NLB.
- If you want the fastest performance w/ low latency use NLB (handles millions of rps).
- If you need to handle protocols that aren't HTTP or HTTPs use NLB.
- Any requirement involving Privatelink use NLB.
- Otherwise use ALB.
Launch Configurations and Launch Templates
At a high level these both perform the same task - allowing a user to define the configuration of an EC2 instance in advance. They are documents which allow a user to define:
- The AMI to use, the instance type and size, type of storage & key pair.
- The networking and security groups.
- Userdata and IAM Roles.
Everything you usually define when launching an instance you can define using these documents.
Both Launch Configurations and Launch Templates are not editable - they are defined once & locked. LT however have versions as LT is the newer of the two.
- Launch Templates provide newer feature configurations of EC2.
- AWS recommend always using Launch Templates as they provide all the features of Launch Configurations and more.
- LCs can only be used for EC2 Auto Scaling Group configs - LTs also do this but can also be used to directly launch EC2 instances.
EC2 Auto Scaling Groups (ASGs)
These enable EC2 to scale automatically based on demand placed on the system.
- ASGs use one specific version of a Launch Template (or a Launch Configuration).
- All instances launched in the ASG use this config defined in the LT.
- An ASG has a Minimum, Desired and Maximum size eg (1:2:4) meaning must be a minimum 1 instance, desired 2, maximum 4.
- They keep instances at the desired capacity by provisioning or terminating instances.
- Scaling Policies automatically update the desired capacity based on certain metrics eg. CPU load.
- These can only update the desired capacity to within the specified min or max capacity.
- ASGs try to level capacity across the AZs / Subnets that it is defined in.
- ASGs also health check the EC2s in the group if an instance fails it is destroyed and replaced.
Scaling Policies
- Manual Scaling - user manually adjusts the desired capacity and the ASG handles any provisioning or termination that is required.
- Scheduled Scaling - time based adjustment (for predetermined times when you know demand will spike or dip).
- Dynamic Scaling:
- Simple - a pair of rules - one to provision and one to terminate - eg "If CPU above 50% + 1 instance" "If CPU below 50% -1 instance".
- Stepped Scaling - Bigger +/- of instances based on difference in metric - allows you to react quicker based on how large a spike / dip is.
- Target Tracking - Set a desired metric eg. 40% CPU, ASG provisions or terminates to meet this.
- Scaling based on number of messages in an SQS Queue.
Step Scaling is recommended in nearly all circumstances over Simple Scaling - this is because Step is more flexible it can react to adjust capacity based on how large a difference from a preferred metric there is. Eg. If CPU > 50% add 1 instance, between 60% - 69% add 2 instances, between 71% - 80% add 3 instances. This means large spikes or dips are accounted for adequately.
Auto Scaling Groups - Solutions Architect Exam Hints:
- Autoscaling Groups are free.
- Only costs are for resources built by the ASG.
- Cool downs can be used to avoid rapid scaling (a cool down period is set after each scaling action before another can take place).
- Think about more, smaller instances for granularity - eg. adding 1 small instance to 20 small instances vs adding a third large instance to 2 existing ones.
- Use with ALBs for elasticity. Instances created by an ASG can automatically be added to an ALB to absorb demand.
- ASGs control when and where, Launch Templates define what config the instances have.
ASG Lifecycle Hooks
These allow a user to define custom actions that can occur during ASG actions. These custom actions occur during instance launch or termination transitions. For example when an ASG moves to terminate an instance you could pause it in the terminating state while it performs the custom action of backing up data from the terminating instance. Once the backup is complete the ASG can carry on with termination.
There is much more to this and you can read about it here: ASG Lifecycle Hooks
Auto Scaling Groups (ASG) Health Checks
There are 3 types of health checks which can be used by an ASG:
- EC2 - The default health check used by ASGs. All of Stopping, Stopped, Terminated, Shutting Down or Impaired (not 2/2 status checks) means the EC2 is viewed as Unhealthy.
- ELB - An EC2 in Healthy in this case if it is both Running and passing the ELB health check - because you can use ALB here the health check can be application aware.
- Custom - Instances can be marked Health and Unhealthy by an external system / tool.
There is a health check grace period (default 300s) before health checks start. This gives EC2 an opportunity to launch the system , bootstrap and start an application on it.
SSL Offload and Session Stickiness
There are 3 ways a load balancer can handle secure connections:
- Bridging
- The default mode of an AWS ALB - one or more clients makes one or more connections to a load balancer over HTTPS. These connections are terminated on the ALB and so the ALB needs an SSL certificate attached that matches the domain name attempting to be reached.
- The ALB decrypts the HTTPS traffic to its underlying HTTP understands it and takes actions based on its contents.
- Once the client connection has been terminated the ALB initiates secondary connections to the compute instances it sits in front of - sending the re-encrypted HTTP traffic via SSL to these instances.
- These compute instances also need the same SSL certificated attached to them.
- Pass-through
- The client connects but the load balancer just passes the connection along to a backend instance - the load balancer doesn't decrypt the traffic at all. The instances still need to have the SSL certificates installed but the load balancer doesn't. In AWS it is the Network Load Balancer that can perform this function.
- Offload
- The same as bridging but secondary connections use HTTP rather than HTTPS. The connection between the ALB and the Compute instances is not encrypted.
Session Stickiness:
With no session stickiness connections are distributed across all in-service backend instances - depending on how the application handles state this could cause user log offs and things like shopping cart losses. AWS Application Load Balancers have an option called Session Stickiness which will always send a connection from a particular user to the same server.
Where possible applications should be configured to use stateless servers - where the state is stored not on the servers themselves but somewhere else like Dynamo DB - this way session stickiness doesn't matter - as all the servers can access the state for a particular user at any time.
Gateway Load Balancers (GWLB)
- GWLB helps you run and scale 3rd party (non-aws) security appliances - Firewalls, Intrusion Detection etc.
- Traffic enters and leaves via GWLB endpoints.
- The GWLB itself then load balances traffic across backend EC2s hosting the 3rd party security software/tools.
- Packets that enter the GWLB are sent to the backend instances completely unaltered using the GENEVE protocol.
Serverless Architecture
"The serverless architecture is a way to build and run applications and services without having to manage the infrastructure behind it. With a serverless architecture, your application still runs on servers, of course, but the server management is done by AWS. So you focus purely on the individual functions in your application code." - Event Driven Architecture
Within a serverless architecture you break up your application into its composite functions and run these separately from and in congress with each other on a serverless compute platform like AWS Lambda. This allows you to make large savings through only running compute power when it is actually needed and additionally be more agile with your upgrade process and tooling choices.
AWS Lambda Basics
- Lambda is Function-as-a-service (FaaS) - it runs short and focussed bits of code (functions).
- A Lambda Function is a piece of code that Lambda Runs.
- Lambda is event driven - an event happens which triggers the function to run - examples might be: a file is added to an S3 bucket, SQS, SNS, DynamoDb Streams etc.
- When you create a Lambda Function you tell it what runtime to use eg. Python 3.9 - this is what will run your code.
- The environment has a direct memory and an indirect CPU allocation - when you create a Lambda Function you specify the amount of memory.
- You are only billed for the duration that a function runs.
- It is a key part of serverless architectures running in AWS.
Lambda supports the following runtimes: Python, Node.js, .Net, Go, Ruby & Java. It is possible to use a custom runtime eg. Rust by using a Lambda Layer, Layers provide a convenient way to package libraries and other dependencies that you can use with your Lambda functions.
Lambda environments are stateless- no data is held after the end of the function. So you have to assume that every time your function is invoked that it is in a brand new environment.
Lambda Limits:
Lambda Functions can have anywhere between 128MB and 3GB of Memory in 64MB steps - this is user specified. The function also has 512MB of mounted storage that your code can use - but it will be blank every time the function is invoked. The function can run for maximum 900s (15minutes) at most - they will timeout after that.
Permissions:
Permissions and security is defined by a Lambda Execution Role - this defines what AWS products and services the function can access.
AWS Lambda in-depth
Networking:
Lambda has two networking modes: Public and VPC.
By default Lambda Functions are given public networking, they can access public AWS services (SQS, DynamoDB, S3) and the public internet. The standard Lambda Functions offer the best performance as no customer specific VPC networking is required. However they have no access to VPC based services unless public IPs are provided and security controls allow external access.
Lambda Functions can be configured to run inside a private subnet in a VPC that is specified by the user. Within the VPC they obey all VPC networking rules. Unless the VPC networking provides a route to the public internet (eg. NAT Gateway & Internet Gateway) they will not be able to access it. Lambda functions within a VPC will run like any other VPC based resource.
Security:
Each function has a Lambda Execution Role which is assumed by the Lambda Function and the permissions within are used to generate the temporary credentials that Lambda uses to interact with other services. For example Role may provide permissions to Read and Put content into certain S3 buckets.
Lambda also has resource policies (similar to an S3 bucket policy) - these resource policies control what services and accounts can invoke lambda functions.
Logging:
- Lambda uses Cloudwatch, Cloudwatch Logs & X-Ray for different aspects of its monitoring and logging.
- Logs from Lambda Executions are stored in CloudWatchLogs.
- Metrics - invocation success/failure, retries, latency is stored in CloudWatch.
- Lambda can be integrated with X-Ray for distributed tracing.
- CloudWatch Logs requires permissions via the execution role - this is in the default role created when you create a Lambda Function.
Invocation:
There are 3 ways to invoke a Lambda Function:
- Synchronous Invocation
- Something (API/CLI etc.) invokes a lambda function, passing in data and waits for a response. The function finished and responds with data.
- This is the invocation type that is used when a client interacts with a function through API Gateway.
- Errors or retries have to be handled by the client - the function runs once and either succeeds or fails and responds.
- Asynchronous Invocation
- Typically used when AWS services invoke lambda functions.
- A service sends an event through to Lambda and doesn't wait for a response - it forgets as soon as the event is sent.
- Lambda handles reprocessing on failure (between 0 & 2 retries) - This means the Lambda Function needs to be idempotent - reprocessing a result should have the same end state.
- Event Source Mappings
- Typically used on streams or queues that don't generate events - things where some sort of polling is required.
- The Event Source Mapping polls queues or streams for data - this data is broken up into batches and sent to Lambda in the form of an Event Batch.
- Permissions from the Lambda Execution Role are used by the ESM to interact with the event source (eg. Kinesis).
Lambda Versions:
- Lambda functions have versions - v1, v2, v3 etc.
- A version is the code + the configuration of the Lambda Function.
- A version is immutable - it never changes once published and has its own ARN.
- Lambda has the concept of $Latest which points at the latest version of a function.
- Aliases (eg. DEV, STAGE, PROD) point at a version and these aliases can be changed to point at different versions.
CloudWatch Events and EventBridge
EventBridge is slowly replacing CloudWatch Events - it performs all the same functionality and more. They can both track anytime an event happens within an AWS service - eg. an EC2 is turned on/off, a bucket is created etc. EventBridge can also track 3rd party events from non-AWS services.
- They both allow an architecture to be implemented of if X happens, do Z. Or at Y time(s) do Z.
- EventBridge is basically CloudWatch Events v2 - best practice is to use EventBridge.
- Both services used what is called an Event Bus - a stream of all the events happening in supported AWS Services.
- EventBridge can use custom Event Buses for 3rd party events.
- Rules match incoming invents on the Event Bus - or schedule based rules which are similar to CRON.
- These events are then routed to one or more targets - eg. a Lambda Function.
Simple Notification Service (SNS)
A highly available, durable, secure messaging service. It is a public AWS service which can be connected to via a Public Endpoint.
- It coordinates the sending and delivery of messages.
- Messages are payloads under 256KB.
- SNS Topics are the base entity of SNS - this is where the permissions and configuration are defined.
- Topics have Publishers (which send messages to the Topic) and Subscribers which receive all of the messages sent to a Topic.
- Subscribers can be things like HTTP(s) endpoints, Email, SQS, Mobile Push / SMS Messages and Lambda Functions.
- SNS Is used across AWS for notifications - for example CloudWatch uses when alarms change state.
- With SNS and certain subscribers you can use delivery status to understand if a message was received
- It also has Delivery Retries.
- It is a regionally resilient service.
- Capable of Server Side Encryption.
- Topics can also be used Cross-Account - by specifying it in a Topic Policy.
AWS Step Functions
Step Functions runs automated workflows specified by the user and can be used to address some deficiencies / limitations in Lambda:
- Lambda is designed as FaaS - to run short focussed code and should not be used to run a full application in one function - partly because it has a 15 minute duration limit.
- Although you could chain Lambda's together to get another 15 minutes - it gets messy at scale and you still have to deal with the issue of Lambda Functions being stateless.
- Step Functions allow users to create serverless workflows with what are called State Machines - it has a Start point and an End Point and in between there are States.
- States are Things (steps) which occur inside these workflows.
- The maximum duration for state machine workflows in Step Functions is 1 year (a lot longer than 15 minutes).
- There are two types of workflow in Step Functions: Standard Workflow (Default - 1 year execution limit) and Express Workflow (5 minute duration limit).
- A state machine can be started via API Gateway, IOT Rules, EventBridge, Lambda and more.
- State Machines have an IAM Role they assume for permissions within AWS.
Types of state:
- Succeed or Fail
- Wait - holds or pauses processing until a duration has passed or specific point in time.
- Choice - allows the state machine to take a different path based on a parameter.
- Parallel - allows for parallel branches in a state machine - to perform multiple sets of things at the same time.
- Map - accepts a list of things - for each item in the list it performs an action or set of actions.
- Task - Represents a single unit of work performed by the state machine - can be integrated with lots of services - Lambda, Batch, DynamoDB etc. Configuring this is how the state machine can actually perform work.
The architecture of a State Machine is that it coordinates work occurring - the actual work is done by the services (Lambda etc.) specified in Task states.

AWS API Gateway
- A service that lets users create and manage APIs.
- It acts as an endpoint / entry point for Applications.
- Sits between applications and integrations (services like Lambda, SNS, DynamoDB).
- It is highly available, scalable, handles authorisation, throttling, caching, CORS, transformations and more.
- API Gateway can connect to services & endpoints in AWS or on-premises.
- API Gateway Cache can be used to reduce the number of calls made to backend integrations and improve client performance.
API Gateway Authentication:
- API Gateway can integrate with Cognito for authentication - a client authenticates with Cognito - receives a token - client passes token to API Gateway - API Gateway verifies its validity with Cognito.
- Another method available is for the client to call the API Gateway with a bearer token (ID) - The Gateway calls a Lambda Authorizer function which then calls an external identity provider - if this passes the Lambda then returns an IAM Policy to the Gateway for the user's permissions.
API Gateway Endpoint Types:
- Edge optimised - any incoming requests are routed to the nearest CloudFront POP (point of presence)
- Regional - used for clients to access from within the same region.
- Private - Endpoints that are only accessible within a VPC (so you can deploy completely private APIs)
API Gateway Stages:
- APIs are deployed to stages - each stage has one deployment (you might have a Prod stage and a Dev stage)
- You can enable canary deployments on stages - say you are looking to release V2 of your API - you can push this to a substage of your main stage and route only a small percent of traffic to this new API code - that way you can test for any errors that might occur in Production. If all goes well you can promote this canary substage to be the main stage.
API Gateway SAA Exam Facts & Figures:
- API Gateway Error Types:
- 4XX - Invalid request on the client side.
- 400 - Bad Request - Generic
- 403 - Access Denied - Authorization has failed
- 429 - Request is being throttled
- 5XX - Valid request but a backend issue.
- 502 - Bad Gateway Exception - bad output returned by the backend.
- 503 - Service Unavailable - backing endpoint is offline
- 504 - Integration failure/timeout
Simple Queue Service (SQS)
SQS queues are a managed message queue service in AWS which help to decouple application components, allow Asynchronous messaging or the implementation of worker pools.
- SQS is a fully managed public service - accessible anywhere with access to AWS Public Space endpoints.
- There are two types of queue: Standard and FIFO.
- FIFO is ordered first in first out. - FIFO guarantees a message will be delivered exactly once in the same order it was added.
- Limit of 3,000 messages per second with batching or up to 300 messages without
- Standard is best effort ordered but may not always be first in first out - the same message may be delivered twice when polled.
- Scales far better and more linearly
- Messages are limited to 256KB in size.
- Messages are received by clients which actively poll the queue.
- Messages have a visibility timeout - Once messages are received by a client / service they are hidden for a certain amount of time. If the client does not explicitly delete the message from the queue after it is done processing it, then the after the "visibility timeout" duration the message will reappear in the queue. This ensures fault tolerance in case a client fails during message processing.
Dead Letter Queue - this is a type of queue in SQS which handles problem messages. For example if a message is retried 5 times and always fails you can move it to the Dead Letter Queue for specific error processing.
SQS is great for decoupling architecture - one service adds a message to the queue and another picks the message up - neither service has to be aware of the other.
Queues are also great for scaling: ASGs can scale and Lambdas be invoked based on queue length.
Important for the SAA Exam: SNS & SQS Fanout architecture - as one message can only cause one event to take place, a popular architecture is to have a message come into an SNS Topic and have multiple SQS Queues subscribed to that Topic - so the message in the SNS Topic is added to those multiple SQS Queues causing multiple events to happen simultaneously. Eg. Transcoding an uploaded video into 480, 720 and 1080p in parallel.
Billing: Charges are based on requests. One request is 1-10 messages up to 256KB in total.
Encryption:SQS supports encryption at rest via KMS - it supports encryption in-transit by default.
Kinesis Data Streams
- It is easy to confuse Kinesis and SQS but they are actually very different products.
- Kinesis is a scalable streaming service that is able to ingest data from lots of different sources.
- Streams can scale from low to near infinite data rates.
- It is a public service and highly available by design.
- Kinesis is built on the concept of Producers and Consumers
- Producers produce data - eg. IOT, a Mobile App, Point of Sale software etc.
- Producers send data into the Kinesis Stream
- It is from this stream that Consumers read and process the data.
- Streams store a 24-hour moving window of data. - this can be increased to 7 days for additional cost.
- Multiple consumers can access data from that moving window - they can access data at different levels of granularity - eg. one consumer processing realtime data as it comes in and one checking every minute or x minutes.
Kinesis Stream Shards: Streams are built out of shards, and more shards are added to the stream as data requirements increase. Each shard in a stream enables 1MB of Ingestion (from producers) and 2MB of consumption per second. The more shards in a stream the more expensive it will be. Data is equally spread across shards in the form of 1MB Kinesis Data Records - all data that enters the stream is stored in these records and these records are spread across shards to ensure a shared data load.
SQS vs Kinesis Exam Tips:
- If the exam questions is about the ingestion of data - at scale, with large throughput or number of devices it is likely referring to Kinesis.
- If it is about worker pools, decoupling or asynchronous communications SQS is the right choice.
- SQS typically has one thing or one group of things sending messages to a queue - these messages are picked up by 1 consumption group.
- It won't have thousands of devices producing and sending data to one queue.
- SQS queues are designed for decoupling applications through asynchronous communications (one service in your application doesn't have to be aware of others)
- SQS also has no persistence of messages - no window like Kinesis. Once the message is received and processed the next step is deletion - they are not held onto.
- Kinesis is designed for huge scale ingestion of data
- It is designed for multiple consumers each of which might be consuming data at different rates - these consumers can pick and process data from any point in the rolling window.
- used for data ingestion, analytics, monitoring.
Kinesis Data Firehose
Kinesis Data Firehose: - this can move data en masse that arrives into a Kinesis Stream to another AWS service - for example s3. This enables data persistence - as otherwise data only exists in the stream for as long as the rolling window allows. It can also move data to third party providers.
- Often used to load data into data lakes, data stores and analytic services.
- It offers Near Real Time delivery (60 second delay or so). It is not a Real Time solution.
- Firehouse waits for 1MB of data or 60 seconds to pass before delivering data.
- It supports the transformation of data on the fly through Lambda (this can add latency however).
- You are billed according to the volume of data that moves through Firehose.
Acceptable destinations for data moving through Firehose are:
- HTTP endpoints - used for moving data to third parties outside AWS.
- Splunk
- AWS Redshift
- ElasticSearch
- S3
Kinesis Data Analytics
Kinesis Data Analytics: the easiest way to analyse streaming data, gain actionable insights, and respond to your business and customer needs in real time.
it is part of the kinesis family of products and is capable of operating in realtime on high throughput streaming data.
- A service that provides real time processing of data.
- Uses SQL to perform queries on the data in real time.
- Ingests directly from Kinesis Data Streams or Firehose.
- After data is processed it is sent onto destinations:
- Firehose - and by extension all of the destinations Firehose supports - keep in mind though that if you send it to Firehose the processing becomes Near Real Time.
- AWS Lambda - Real Time
- Kinesis Data Streams - Real Time
- This service sits in between two data streams - a source stream that it ingests data from and a destination stream it sends data too.
Use Cases:
- Anything using streaming data but needs real time SQL processing.
- Real Time Dashboards (leader boards for games).
- Real Time Metrics.
Amazon Cognito
Amazon Cognito provides Authentication, Authorisation and User Management for Web & Mobile Apps.
- Cognito User Pools - provide sign in through JSON web tokens (JWT) - however most AWS Services don't accept JWT so this is mainly useful for Web Apps and Mobile Apps.
- Provides User directory management, profiles, sign-up and sign-in (through a customisable web UI), MFA and more.
- Can also allow social sign in via 3rd party Identity providers - like Google, Facebook, SAML.
- Cognito Identity Pools - allow you exchange a type of identity for temporary AWS Credentials - to access AWS Services.
- Through this you can swap Federated Identities like Google, Facebook, SAML and User Pool identities for AWS Credentials.
- Can also allow unauthenticated users to perform strict actions like logging high-scores from a Mobile App in a DynamoDB database.
Cognito Solution Architect Associate Exam Tips:
- User Pools are about log in and managing user identities. - Tokens provided by User Pools do not themselves enable access to AWS Resources.
- Identity Pools are about swapping identities for temporary AWS Credentials to enable access to AWS Resources.
Content Delivery and Optimisation
CloudFront Architecture
CloudFront is a content delivery network (CDN) - it's job is to improve/optimise the delivery of content to viewers and users of that content. It does this through caching data in a global network.
It solves the issue of users accessing content from an application stored thousands of miles away (which is slow with high latency). Instead of those users being delivered the content from the location of the application they retrieve the data from a close edge location where the data is cached.
CloudFront Terms:
Origin - The source location of the content (where it is served from) - this is either S3 Origin or a Custom Origin.
Distribution - The 'configuration' unit of CloudFront. The things specified in this distribution are:
Edge Locations - A local cache of data - these are distributed globally close to customers. There are over 200 of them.
Regional Edge Cache - Larger version of an edge location. Generally used to store things which are accessed frequently.
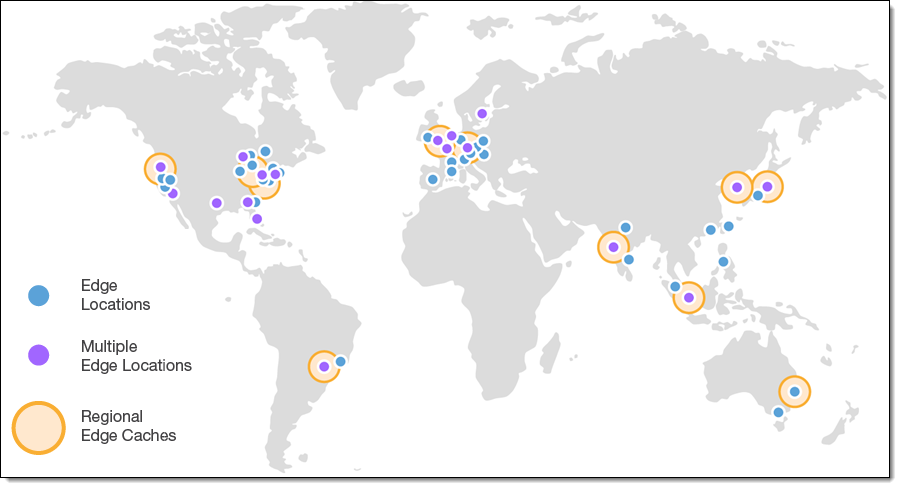
CloudFront is for download operations only - any uploads go directly to the origin - It does no write caching, only read caching.
Distributions in Detail:
As mentioned a distribution is the primary unit of configuration in CloudFront - They are deployed to edge locations. The things specified within them are:
- Your content origin— S3, Custom - You can specify any combination of up to 25 origins for a single distribution.
- Access—whether you want the files to be available to everyone or restrict access to some users.
- Security—whether you want CloudFront to require users to use HTTPS to access your content.
- Cache key—which values, if any, you want to include in the cache key. The cache key uniquely identifies each file in the cache for a given distribution.
- Origin request settings—whether you want CloudFront to include HTTP headers, cookies, or query strings in requests that it sends to your origin.
- Geographic restrictions—whether you want CloudFront to prevent users in selected countries from accessing your content.
- Logs—whether you want CloudFront to create standard logs or real-time logs that show viewer activity.
CloudFront Behaviours: - These are part of a distribution and are actually responsible for a lot of the settings specified in distributions.
Behaviours sit in between origins and the distribution deployed to edge locations. Behaviours contain rules which match data requests and can route requests for data to different origins. An edge location will send a request for data to the origin if the edge location doesn't have the data cached but it has been requested by a user. For instance the default rule is * (star - match all) this is a catch all the will route requests that don't match any other rules (if other rules exist) to an origin. However an application might have a specific origin (eg an S3 bucket) for all its images so you could implement a rule in a behaviour that says if the request for data matches "img/*" then route the request to X s3 bucket.
Behaviours are also used to configure: Origins, Origin Groups, TTL, Protocol Policies & Restricted Access.
TTL and Invalidations
In general you want edge location caches to have more frequent Cache Hits than Cache Misses, meaning that user requests for data are served by the edge location and don't have to go back to the origin. As this means lower load on your origin and better performance for your users. With that in mind it makes sense that we want to ensure all the most popular data is stored at the edge location and any data that becomes unpopular is removed.
The Default Time To Live (TTL) is 24 hours - any objects cached by CloudFront will have a a TTL of 24 hours. After this period an object will be viewed as invalid - it is not deleted but when a user requests the object the edge location won't respond with data right away, instead it will check with the origin to see if the object has been changed in anyway (newer version etc).
If the object has been changed the origin will reply with the new version of the object and that will be both sent to the user and cached at the edge location. If the object has not been changed then the origin will reply no change and the object will remain in its current state cached at the edge location with a renewed TTL.
Cache Invalidations: You set these on a distribution with a match rule eg. img/* and it will apply to all edge locations invalidating all objects that match the invalidation. This is not immediate and does take time.
CloudFront Time To Live SAA Exam Tips:
- More frequent cache hits = lower origin load.
- Default TTL is 24 hours.
- You can set per object TTL (so objects use this rather than the default) with the following Origin headers:
- Cache-Control max-age (Sets the TTL in seconds)
- Cache Control s-maxage (Also sets TTL in seconds - essentially same as above)
- Expires (Set a date and time for the TTL)
- These headers are set via the origin eg. in object metadata on S3
- You can also set max and min TTL on the behaviours for your cloudfront distribution which will limit how large or small these headers can make an objects TTL.
- Cache Invalidations - set on a distribution, invalidate data in your cloudfront caches and applies to all edge locations with a cache but is not immediate. It is based on a matching rule eg. img/*
- This is expensive and intensive - a better option can be to version your file names eg img_v1, img_v2 and update your application to point at the latest version rather than rely on Cache Invalidations (Don't confuse this with enabling versioning in S3).
AWS Certificate Manager (ACM)
The AWS Certificate Manager is a service which allows the creation, management and renewal of certificates. It allows deployment of certificates onto supported AWS services such as CloudFront and ALB.
- Certificates prove identity - they are signed by a certificate authority.
- You can not use ACM to provision Certificates on EC2.
- It manages the automatic renewal of certificates.
How SSL Certificates work:

CloudFront SSL
Users access content in CloudFront via a domain record (CNAME) - there is one provided by default for each distribution that will look something like "https://a333333dwedwe.cloudfront.net/". The default domains always end in .cloudfront.net - they also are all supported by a default SSL certificate via a *.cloudfront.net cert.
You can implement your own domain name instead of the default if that is what you would rather users see, eg. cdn.myapp...
If you do this then you will need to use a matching certificate for this domain in your CloudFront Distribution and this can be done via ACM. Now normally ACM is region specific but in the case of global services like CloudFront you provision the certificate specifically in us-east-1.
Cloud Front SSL Solutions Architect Exam Help:
- SSL is supported by default on the default domain - via the *.cloudfront.net certificate.
- When using a custom domain instead of the default CloudFront Distribution domain you need to provision a matching SSL certificate to use HTTPs.
- When using AWS Certificate Manager (which is region specific) to create the certificate for the custom domain, you create it in us-east-1as CloudFront is a global service.
- There are two SSL connections - Viewer to CloudFront & CloudFront to Origin, both need valid Public Certificates - Self Signed Certs will not work with CloudFront.
- CloudFront charges extra if you need a dedicated IP (over $600 per month) (but you only need a dedicated IP in order to support very old pre-2003 browsers).
Securing CloudFront
When thinking about CloudFront security and the CloudFront delivery path there are a few elements to take into account:
- The origins being used (eg. S3).
- The CloudFront Network itself.
- The Public internet and the users.
Origin Access Identity (OAI) - is a type of identity that can be associated with CloudFront Distribution, when the Distribution is accessing an S3 origin it "becomes" the OAI. You can give the OAI access in the Bucket Policy of the origin bucket. Generally for origin buckets you want to lock them down to only be able to be accessed by CloudFront (so one or more OAIs).
OAIs only apply to S3 Origins - so for Custom Origins we need to do something different:
- We can configure CloudFront to send a custom HTTPs header from the edge location in requests to the Origin. If the Origin does not receive this header it won't respond.
- This means the origin can not be accessed directly (skipping CloudFront) as requests will not have the required custom header.
- Another option would be configure a firewall on the Custom Origin to only accept requests from the IP range of CloudFronts servers (which AWS does publish).
To protect users and viewers we can insist that HTTPs is used when making requests to CloudFront.
Lambda@Edge
This is a feature of CloudFront that allows you to run lightweight Lambda Functions at edge locations that adjust data between the viewer (user) and the origin.
- Currently only Node.js and Python are supported as runtimes
- Can't use VPC Lambdas
- Layers are not supported
- They have different limits (time etc.) to standard Lambda.
You can use this for example for A/B testing - you could alter a viewers request to be a different version of the content a % of the time.
You could use this to customise behaviour based on the type of device a user has.
Global Accelerator
AWS Global Accelerator is designed to improve global network performance by offering an entry point onto the global AWS transit network as close to customers as possible.
This service uses 2 Anycast IP Addresses for each Global Accelerator created by customers - these are IPs that aren't limited to one device. These Anycast IP addresses are shared across all Global Accelerator Edge Locations and if a user connects to one of those IPs they will be routed to the closest edge location to them. So even though two users might be using the same IP the destination they connect to might be completely different.
This initial connection to the Global Accelerator Edge Location is done over the public internet - but now all data flows through the AWS Global Network which has less hops, is under AWS control and offers significantly better performance. Effectively this brings the AWS Network a lot closer to the user.
Global Accelerator vs CloudFront SAA Exam Tips:
- Global Accelerator moves the AWS Network closer to customers.
- Global Accelerator transits traffics to 1 or more locations.
- CloudFront moves content closer to customers.
- In Global Accelerator, connections enter at edge locations using anycast IPs.
- Global Accelerator is a network product - is used for non HTTP/S data like TCP/UDP.
- Global Accelerator doesn't cache anything.
- CloudFront caches HTTP/S data and content.
Advanced VPC Networking
VPC Flow Logs
VPC Flow logs is a feature allowing the monitoring of traffic flow to and from interfaces within a VPC.
- They only capture packet metadata - they don't capture packet contents.
- They work by attaching monitors within a VPC and they can be attached at 3 different levels:
- To the VPC - Monitors all ENIs in that VPC.
- To a Subnet - Monitors all ENIs in that Subnet.
- Directly to a specific ENI - Monitors only that interface
- Flow Logs are not real time - there is a delay from traffic passing through the VPC to it showing up in the Flow Logs.
- The logs can be configured to go to S3 or CloudWatch Logs.
- Flow Logs stored in S3 can be queried by Athena using SQL like language.
Egress Only Internet Gateway
Egress-Only internet gateways allow outbound (and response) only access to the public AWS services and Public Internet for IPv6 enabled instances or other VPC based services.
- With IPv4, addresses are private or public. Private addresses can not directly communicate with the public internet without a go between (NAT Gateway).
- A NAT Gateway does not allow externally initiated connections to private IPv4 addresses - it only allows the private IP to communicate with the internet and get a response.
- NAT can't be used with IPv6 as IPv6 IPs are all public.
- All IPv6 IPs are public - meaning they are all publicly routeable and allow externally initiated connections. We need to use a tool to allow us to treat IPv6 addresses like a private IPv4 address.
- A standard Internet Gateway allows all IPv6 address to connect to the internet and the internet to connect to them.
- Egress Only Internet Gateways allow for outbound-only connection for IPv6.
- Architecture for this service is exactly the same as a standard Internet Gateway.
VPC Endpoints (Gateway)
- Gateway Endpoints provide private access to S3 and DynamoDB without the need for a NAT or Internet Gateway.
- This means they allow private only resources inside a VPC to access these services.
- When you create a Gateway Endpoint in a VPC the route tables for the subnets configured to use it are edited to include a route for any S3 / DynamoDB requests to be routed to the Gateway Endpoint.
- A Gateway Endpoint is highly available across all AZs in a region by default - you only need to configure which subnets in a VPC will use it.
- The Gateway Endpoint does not exist in a specific subnet.
- Endpoint Policies allow you to configure access control for an Endpoint - for example you can configure a policy to only allow a Gateway Endpoint to access a particular subset of S3 Buckets.
- Gateway Endpoints only allow access to resources in the same region that the endpoint is in.
- This is useful if you want to create VPCs with private only resources (eg. a private EC2 with no public internet access) but still allow those resources to access S3 or DynamoDB.
VPC Endpoints (Interface)
- Just like Gateway Endpoints - Interface Endpoints provide private access to AWS Public Services.
- These can access any Public AWS Service (eg. Lambda, SNS) except DynamoDB (but including S3).
- Interface Endpoints are not automatically Highly Available - Each endpoint is added to a specific subnet within a VPC so in one AZ (a big difference from Gateway Endpoints).
- As they are specific interfaces in a subnet, the access to them can be controlled via Security Groups.
- Can still restrict what can be done/accessed by the Endpoint with Endpoint Policies.
- Interface Endpoints currently only support TCP and IPv4.
- Interface Endpoints function using PrivateLink.
- Rather than using route tables to direct traffic like Gateway Endpoints - Interface Endpoints all have their own DNS Names and Private IPs and this is how connections are made to them in a VPC.
VPC Peering
This is a service that allows you to create a Private and Encrypted network link between two VPCs (and no more than two) - however a VPC can have more than one peering connection. VPC Peering can function in the same region or cross-region and it can be in the same or cross-account.
- This also enables Public Hostnames to resolve to private IPs for all resources in the two peered VPCs. Eg. Connecting to the Public Address of an EC2 in another VPC that is linked by peering will resolve to the private IP of the EC2.
- If the VPCs are in the same region their Security Groups can reference each other.
- VPC Peering does not support transitive peering - If (VPC A is Peered with VPC B) and (VPC B is also peered with VPC C) that does not mean VPC A can communicate with VPC C.
- When setting up Peering you will need to configure the Route Tables for your VPCs with the CIDR ranges of the other VPCs subnets.
- The IP ranges of the VPCs CIDRs cannot overlap for Peering to work.
Hybrid Environments and Migration
For this section it helps to have some understanding for the Border Gateway Protocol - however it wont be directly asked about on the Solutions Architect Exam. Here is a great article explaining BGP.
AWS Site-to-Site VPN
AWS Site-to-Site VPN is a hardware VPN solution which creates a highly available IPSEC VPN between an AWS VPC and external network such as on-premises traditional networks. VPNs are quick to setup vs direct connect, don't offer the same high performance, but do encrypt data in transit.
- They can be fully Highly Available if designed and implemented correctly.
- They are quick to provision - taking less than an hour.
- They consist of a VPC and a Virtual Private Gateway (VPG) along with an external network and a Customer Gateway (CGW) - This service creates a VPN connection between the VGW and the CGW.
- When making a VPN the VGW creates two Endpoints in different AZs - these are the endpoints for two separate VPN Tunnels (which carry encrypted data) linked to the external networks Customer Gateway. This dual tunnel means from the AWS side the VPN is always highly available.
- There can be more than one CGW and if there is the whole VPN can be considered Highly Available however with only one CGW the VPN is only HA on the AWS side as the single CGW in the external network is a single point of failure.
There are two types of VPN:
- Static- Uses static network configuration - Static routes are added to the route tables and static networks are configured on the VPN connection.
- Dynamic - Uses the border gateway protocol - Creates a relationship between the VGW and the CGW which can communicate available routes and the state of links between them.
- Ca enable route propagation with this allows routes to be added to route tables as soon as they are learned by the VGW.
Site-to-Site VPN Exam Tips:
- All VPNs have a speed limit of 1.25Gbps
- VPNs transit over the public internet - causing inconsistency and often higher latency.
- Billed by hourly cost as well as by GB out.
- They are quick to set up (hours or less) as it is all software configuration.
- They can be used as a backup for Direct Connect.
Direct Connect (DX)
- This is a 1Gbps or 10Gbps Network Port into the AWS Network.
- The port is allocated at a DX location (a datacentre which are located globally).
- It connects to a customer router which must be capable of using VLANS and BGP.
- To connect to this DX Port the customer will either need their own router in the DX Location or work with a partner who has a router in the DX Location.
- Then a customer needs to arrange to extend this into their on premises business location - actually extending a physical fiber cable.
- This can take weeks or months to provision as it is physical infrastructure implementation.
- Direct Connect is unencrypted - you would need to run a site-to-site VPN over the top to encrypt the data.
- You can run Multiple Virtual Interfaces (VIFS) over one DX. These represent connections into your AWS Infrastructure.
- There are two types of VIF:
- Private VIF (Connected to a VPC) - Each VIF connects to one VPC.
- Public VIF (Public Zone Services - S3, DynamoDB, SNS etc.) - This can only connect to public AWS services, not the public internet.
Direct Connect (DX) AWS Solutions Architect Exam Tips:
- Takes much longer to provision than a VPN (takes weeks at least).
- DX Port Provisioning is quick but the cross-connect takes longer.
- Because cross connect involves a physical fiber link from the port to on-prem.
- This extension to on prem can take weeks/months.
- You can use a VPN first then request it replaced with a DX.
- Direct Connect is capable of much higher speed than AWS VPN.
- Up to 10Gbps on a single port.
- Up to 40Gbps with Aggregation.
- Low Latency - also doesn't use business bandwidth.
- No Built In Encryption - can run VPN over top of it for encryption.
Transit Gateway
The AWS Transit gateway is a network gateway which can be used to significantly simplify networking between VPC's, VPN and Direct Connect.
- This service is a Network Transit Hub that connects VPCs to on premises networks.
- It is a network gateway object and like others it is Highly Available and Scalable.
- Has attachments to other network types: VPC, Site-to-Site VPNs, Direct Connect.
Effectively this service can sit in between a network containing multiple VPCs, On premise connections via VPN and Direct Connect and act like a router for all the traffic between them.
This is needed as otherwise in the example image below the VPCs would need 6 Peering Connections, The Direct Connect would need 4 connections one for each VPC, and the Customer Gateway VPN would also need 4 connections one for each VPC. Without a Transit Gateway complicated networks become admin heavy and scale badly.
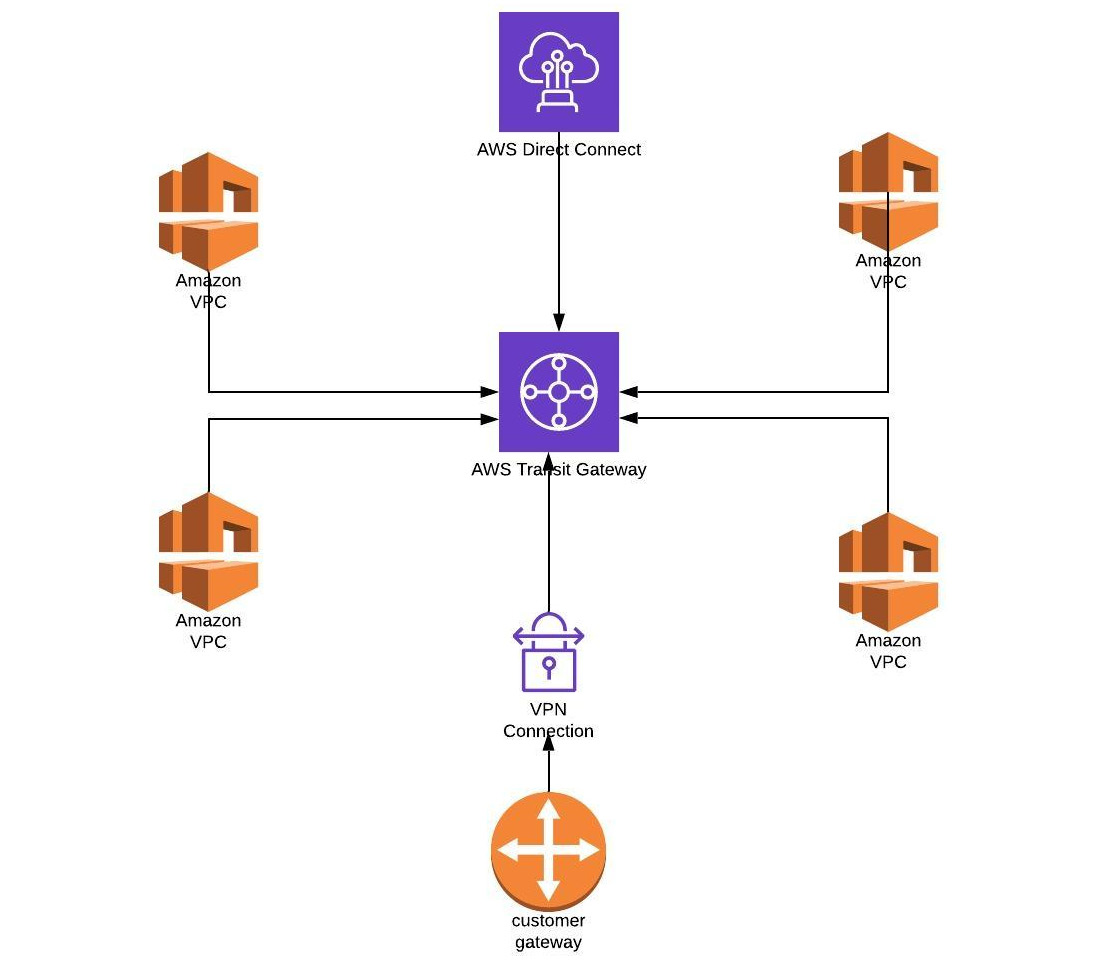
You can even peer Transit Gateways together across regions and accounts. Meaning you can create very complicated global networks without the admin overhead that would otherwise be required.
Transit Gateway SAA Exam Tips:
- Can connect VPCs, Direct Connect and VPNs together..
- It does support Transitive Routing - If (VPC A is connected to the TG) and (VPC B is connected to the TG) then VPC A can communicate with VPC B.
- Transit Gateways can be peered with other Transit Gateway across regions and accounts to create global networks.
- Can be shared between accounts using AWS RAM.
- Way less network complexity vs not using a Transit Gateway in multiple VPC setups - especially if on premises DX and VPN connections are needed also.
Storage Gateway
- A virtual storage appliance to be used on-premises (not relevant for SAA but can be used in AWS itself in some cases).
- Allows for the extension of on-premises file and storage capacity into AWS.
- Also allows volume storage backups to be stored in AWS.
- Allows Tape backups to be synced into AWS.
- Allows for migrations into AWS.
- Storage Gateway has multiple modes:
- Tape Gateway (VTL) Mode: configures storage gateway so that to backup servers it looks just a tape drive. Virtual Tapes are stored in S3.
- File Mode: Creates file shares using SMB and NFS.
- Maps files on S3 Objects.
- Volume Mode: like EBS but running on premises
- Block storage backed by S3 and EBS Snapshots.
Snowball, Edge & Snowmobile
- All 3 are designed to move large amounts of data in or out of AWS.
- These use physical storage units transferred between on-premises and data centres - either suitcase sized or carried on trucks.
- These can be ordered Empty, Loaded up and returned
- Or ordered with data, emptied into on prem and returned.
Snowball:
- Ordered from AWS - device is physically delivered to you (so not instant).
- All data on the Snowball is encrypted using KMS.
- They either have a 50TB or 80TB capacity.
- Snowballs can be connected to using either 1Gbps or 10Gbps networking.
- The economical range for using Snowball is needing to transfer 10TB to 10PB of data (vs using the AWS network).
- You can order multiple devices (to multiple business premises if needed).
- Snowball only includes storage - no compute capcity.
Snowball Edge:
- Like standard Snowball but also offers compute.
- Has a larger capacity vs Snowball.
- Faster Networking as well: 10GBps, 10/25 (SFP), 45/50/100 Gbps (QSFP+).
- Ideal for remote sites where data processing is required as it's ingested (also if faster networking is needed).
Snowmobile:
- Portable Datacentre within a shipping container on a truck.
- Needs to specially ordered and isn't available everywhere.
- Ideal for a single location which needs 10PB or more of data to be sent into AWS.
- Up to 100PB per snowmobile.
- It is a single truck - not compatible with smaller or multi site (unless all sites are huge).
AWS Directory Service
What is a directory:
A directory stores identity objects: Users, Groups, Computers, Servers, File Shares etc. This all has a structure called a domain/tree. Multiple trees can then be grouped into a forest. This is a common architecture in Windows Environments. It enables Single Sign On like capability - with centralised management for identity objects.
One of the most popular directory services is Microsoft Active Directory Domain Services (AD DS) but there is also others eg. open source Samba.
AWS Directory Service:
- An AWS managed implementation of a Directory.
- Runs within a VPC (a private service).
- Some AWS services need a directory - eg. Amazon Workspaces.
- It is a AWS Based directory that other AWS Services can use for identity purposes.
- It can be isolated or integrated into an existing on-premises system.
- Or act as a proxy back to on-premises (just passes back requests to on-prem).
AWS DataSync
Orchestrates the movement of large scale data (amounts or files) from on-premises NAS/SAN into AWS or vice-versa.
- It is a data transfer service allowing customers to move data to and from AWS.
- It is done over a network - not physically like Snowball.
- Used for migrations, data processing transfers, enable archival/cost effective storage.
- Designed to work at a huge scale.
- Keeps metadata (eg. permissions & timestamps).
- Built in data validation - can ensure that as data arrives in AWS it matches the original data.
- Highly scalable - 10Gbps per agent (~100TB per day)
- Supports Bandwidth Limiters - in case you need to throttle the rate at which data is transferred to prevent all your bandwidth being hogged.
- Supports Incremental and scheduled transfer options.
- Supports compression and encryption.
- Supports automatic recovery from transit errors.
- Automatically handles integrations with AWS services (S3, EFS, FSx) and can even be used to transfer data between services.
- Pay as you use service - per GB cost for data moved.
DataSync Architecture Definitions:
Task - A 'job' within DataSync, defines what is being synced, how quickly, From where and To where.
Agent - Software used to read or write to on-prem data stores using NFS or SMB.
Location - every task has two locations From and To. Eg. Network File System (NFS), Server Message Block (SMB), Amazon EFS, Amazon FSx, S3
In order to use DataSync you need to install the DataSync agent in your on-premises environment. This agent communicates with on-prem storage over NFS/SMB protocol and then transfers that data encrypted to AWS. It can recover from failure, use schedulers and limit bandwidth.
DataSync SAA Exam Tips:
- You need to transfer large amounts of data electronically (can't use Snowball).
- Reliable Transfer (over a network) of Large Quantities of Data - It's DataSync.
- Needs to integrate with EFS, FSx, S3 and support Bi-directional Transfer, Schedule Transfer, Incremental Transfer - It's DataSync.
FSx for Windows File Server
FSx for Windows Servers provides a native windows file system as a service which can be used within AWS, or from on-premises environments via VPN or Direct Connect.
- FSx is like EFS for Windows (though architected differently)
- Provides fully managed file servers/shares.
- Integrates with AWS Directory Service or Self Managed on-prem AD.
- Can be single or multi-AZ with in a VPC.
- Can perform on-demand and scheduled backups.
- These file shares are accessible within the VPC, via Peering, VPN or Direct Connect.
- It is a native windows file system.
- Supports de-duplication, Distributed File System (DFS), KMS at rest encryption and enforced encryption in-transit.
Windows FSx SAA Exam Tips:
- Offers Windows Native File Systems / Share in AWS (like EFS for Windows)
- If VSS is mentioned - (Offers User Restores) the answer is FSx.
- Provides Native file systems over SMB - If you see SMB for file system it is FSx.
- This is because EFS uses NFS.
- Uses the Windows permission model.
- If you see DFS (Distributed File System) it is FSx.
- FSx is managed so no admin overhead (no managing servers).
- Integrates with Directory Service and on-prem AD.
FSx for Lustre
FSx for Lustre is a managed file system which uses the FSx product designed for HPC - Linux clients and delivers high performance computing.
- It supports POSIX style permissions for file systems.
- Used for Machine Learning, Big Data, Financial Modelling.
- Offers 100's GB/s of throughput & sub millisecond latency.
- Accessible over VPN or Direct Connect
- Nothing to do with Windows.
FSx for Lustre offers two deployment types:
- Scratch:
- Highly optimised for short term workloads and performant but no replication or HA.
- Persistent:
- Longer term with High Availability (in one AZ) and is self-healing.
FSx for Lustre Solutions Architect Exam Help:
- Not for Windows - Instead for high performant file system workloads.
- Scratch is the deployment for pure performance.
- Used for short term workloads - no HA and no replication.
- susceptible to hardware failure.
- Persistent deployment has replication in one AZ only.
- Used for longer term workloads.
- Auto-heals from hardware failure due to replication.
- You can backup to S3 with both deployments.
- Any mention of machine learning, sage maker or POSIX in relation to a file system - it's FSx for Lustre.
Security and Operations
AWS Secrets Manager
AWS Secrets Manager is a product which can manage secrets within AWS. There is some overlap between it and the SSM Parameter Store - but Secrets Manager is specialised for secrets.
- As the name suggests it is specifically designed for secrets (Passwords, API Keys etc.)
- Can be used via the Console, CLI, API and SDKs. A common use case is integrating it with other applications.
- Supports automatic rotation of secrets (this uses Lambda).
- Directly integrates with some AWS products like RDS.
- Secrets are encrypted at rest and access is governed by IAM.
- While AWS Parameter Store has the ability to store secure strings it can't automatically rotate secrets.
AWS Shield and Web Application Firewall (WAF)
AWS Shield:
- Provides protection against DDoS attacks.
- Shield Standard comes for free with Route 53 and CloudFront.
- Protection against Layer 3 and Layer 4 DDoS Attacks.
- You can use Shield Advanced if you need greater protection - at a cost of $3,000 p/m.
- Increases range of products that can be protected - EC2, ELB, CloudFront, Global Accelerator and R53.
- Provides access to a Real Time - AWS DDoS Response Team.
- Also comes with financial insurance in the event of a DDoS attack (if you have autoscaling set up a DDoS attack can be very costly).
Web Application Firewall (WAF):
- A Layer 7 firewall - it understands HTTP and HTTPS.
- Protects against complex Layer 7 (application layer) attacks.
- SQL Injections, Cross-Site Scripting, Geo Blocks, Rate Awareness.
- Configured using a Web Access Control List (WEBACL) integrated with ALB, API Gateway and CloudFront.
- WEBACL uses rules to evaluate traffic that arrives.
AWS Shield and WAF Exam Tips:
- Shield - Protects against Layer 3 & 4 DDoS Attacks.
- Standard comes free with R53 and CloudFront
- Advanced is $3,000 a month and adds ELB, Global Accelerator and EC2.
- WAF is a layer 7 (application layer) firewall.
- Protects against SQL Injections, Cross-Site Scripting.
- Supports Geo Blocks and Rate Awareness.
Cloud HSM
Similar to KMS in that it creates manages and secures cryptographic keys - however there are a few key differences.
- A True "Single Tenant" Hardware Security Module (HSM).
- The HSM is AWS provisioned but fully customer managed - AWS has no access.
- AWS provision in its own Cloud HSM VPC which is managed by AWS.
- You need to provision more than one HSM in this VPC if you want High Availability (it is not HA by default).
- The HSMs that are in this VPC are injected into your customer managed VPC by Elastic Network Interfaces.
- Where as KMS is not single tenant and it is AWS managed so AWS has at least some form of access to your KMS and keys.
- Cloud HSM is FIPS 140-2 Level 3 Compliant (KSM is only Level 2 - though some of it is Level 3).
- It is not very integrated with AWS - you don't use IAM for permissions / access instead you access it via industry standard APIs - PKCS#11, JCE, CryptoNG.
- KMS can use Cloud HSM as a customer key store - which gives you many of the benefits of Cloud HSM along with the integration given by KMS.
Cloud HSM SAA Exam Tips:
- Cloud HSM creates manages and secures cryptographic keys. More secure than KMS.
- Cloud HSM is FIPS 140-2 Level 3 Compliant (KSM is only Level 2 - though some of it is Level 3)
- A True "Single Tenant" Hardware Security Module (HSM).
- Access not defined by IAM - rather defined by industry standard APIs: PKCS#11, JCE, CryptoNG.
- No native integration between Cloud HSM and any AWS products - eg. you can't use it with S3 Server Side Encryption.
- Cloud HSM can be used to offload SSL/TLS processing from Web Servers.
- Can enable Transparent Data Encryption (TDE) for Oracle Databases.
- Can be used to protect the Private Keys for an issuing Certificate Authority.
AWS Config
AWS Config's primary job is to record configuration changes over time on resources. When enabled, each time a configuration changes for a resource a record is created of the configuration at that time - including the resources relationship to other resources.
- Resource records are stored in S3.
- This service is great for auditing changes and checking compliance with standards.
- You can set standards and AWS Config can check your resources against those standards.
- It does not prevent changes happening - it is not a permissions product or prevention product.
- AWS Config is a regional service - when enabled it checks config in a particular region.
- It can be configured for cross-region and cross-account aggregation.
- Changes can generate SNS notifications and near real time events in EventBridge and Lambda.
Amazon Macie
Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS.
- It can be used to discover, monitor and protect data stored in S3 buckets.
- Can be used for Automated discovery data - personal information, finance info etc.
- Macie identifies and indexes this data so you know what data you have and where it is.
- Macie functions using Data Identifiers:
- Managed Identifiers - built in to the product and use Machine Learning Patterns - it can identify nearly all common types of sensitive data.
- Custom Identifiers - For example you can use Regex to search for specific types of data.
- These Data Identifiers are run through "Discovery Jobs" in Macie.
- Macie uses a multi account architecture - it is centrally managed - for example using AWS Organisations. So all buckets in the Org are evaluated in the same way.
Amazon Inspector
Amazon Inspector is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS EC2. Amazon Inspector automatically assesses applications for exposure, vulnerabilities, and deviations from best practices.
- It scans EC2 instances and the instance OS.
- Identifies vulnerabilities and deviations from best practice.
- Provides a report of findings ordered by priority.
There are two types of assessments that Inspector can perform:
- Network Assessment - Agentless does not require an agent installed on the EC2 instance.
- Network and Host Assessment - Requires an installed agent.
Amazon Inspector SAA Exam Tips:
- Inspector assesses the security of EC2 Instances.
- Inspector can check EC2s for:
- Network Reachability - exposure of EC2 networks.
- Common Vulnerabilites and Exposures (CVE).
- Center for Internet Security (CIS) Benchmarks.
- Security best practices for Amazon Inspector
Amazon GuardDuty
Guard Duty is an automatic threat detection service which reviews data from supported services and attempts to identify any events outside of the 'norm' for a given AWS account or Accounts.
- It is a continuous security monitoring service.
- Works by analysing supported data sources.
- Uses AI and ML plus threat intelligence feeds.
- Identifies unexpected and unauthorised activity in an AWS Account - it learns what is expected itself.
- Can be configured to notify or event-driven protection/remediation using EventBridge and Lambda.
- Supports multiple accounts - can be centrally managed from one account.
CloudFormation
CloudFormation is AWS's built-in Infrastructure as Code tool. Like Terraform specifically for AWS. It is quite a broad topic and the better covered in videos, if you haven't checked it out already Adrian Cantrill's CloudFormation section of his Solutions Architect Associate course is priceless. However this article from Iaas Academy covers the main info you need succinctly for the AWS SAA Exam.
Additionally this video on CloudFormation from Simpli Learn will help you get a foundational understanding of the tool.
NOSQL Databases and DynamoDB
DynamoDB (DDB) Architecture
DynamoDB is a NoSQL fully managed Database-as-a-Service (DBaaS) product available within AWS. Capable of handling Key/Value data or the Document database model.
- There are no self-managed servers or infrastructure to worry about.
- Different to RDS which a a Database Server as a Service product - this is a Database as a Service product.
- Supports a range of scaling options - manual or automatic.
- On-Demand mode available which is set and forget - scaling is handled for you.
- Highly resilient across AZs and optionally can be made globally resilient for extra cost.
- Really fast, single digit millisecond access to data (SSD Based)
- Handles backups, point-in-time recovery, encryption at rest.
- Supports event driven integration - take action when data changes.
Tables are the base entity within DynamoDB - a table is a grouping of items that all share the same Primary Key.
- A table can have an infinite number of items in it.
- Each item must have a unique value for its Primary Key - this is the only restriction on data, items can then have all, none a mixture of attributes or even different attributes
- A primary key can be made up of two values or just one value - there is always a Partition Key and the second optional value is the Sort Key.
- With a primary key composed of one value (the Partition Key) all items must have unique Partition Keys.
- With a composite (two value) primary key it is possible for multiple items to have the same Partition Key but if they do they must all have different Sort Keys.
- DynamoDB has no rigid attribute schema.
- An item can be a max of 400KB in size.
DynamoDB Capacity:
- In DDB capacity refers to speed (performance) not storage.
- Tables can be created with provisioned capacity or on-demand capacity.
- If you provision capacity you need to set it on a per table basis.
- Capacity has two unit types:
- WCU - Write Capacity Units
- 1 WCU set on a table means you can write 1KB per second to that table.
- RCU - Read Capacity Units
- 1 RCU means you can read 4KB per second from that table.
DynamoDB Backups:
There are two type of backup available:
- On-Demand
- Similar to RDS Snapshots - they retain a full copy of table until you manually remove the backup.
- Can be used to restore a table or migrate a table within the same or to a different region.
- Point in Time Recovery
- Disabled by default - enabled on a table by table basis.
- When enabled creates a continuous record of changes and allows replay to any point in a 35 day time window.
- Has a 1 second granularity - can restore to any 1 second within the 35 day window.
DynamoDB Solution Architect Associate Exam Tips:
- Any question mentioning NoSQL - preference DynamoDB in your answer.
- Any questions mentioning Relational Data - generally not DynamoDB as it is not built for relational databases.
- Any mention of Key/Value DBs - Preference DynamoDB
- Access data via the console, CLI or API - it is NoSQL so you can't use SQL for queries.
- Billing is based on the RCU, WCU, Storage and features enabled on a table.
DynamoDB - Operations, Consistency and Performance
Reading and Writing:
- When you have an unknown or unpredictable workload or need low admin the best option is On-Demand capacity.
- Remember capacity refers to performance not storage.
- With On-Demand you pay per million read or write units - but this can be up to 5 times more expensive than provisioned capacity.
- Provisioned capacity is better for known workloads and lower costs.
- With Provisioned capacity you set the RCU and WCU on a per table basis.
- The minimum allowed provisioned settings are 1 RCU and 1 WCU per table.
- Every table has an RCU and a WCU burst pool - this is 300 seconds of the Read and Write capacity units of the table.
Operations:
- The two most common operations performed on a DDB table are Query and Scan.
- Query:
- Can only query on the Partition Key or the Partition Key and Sort Key together.
- Capacity consumed is the size of all returned items.
- Any further filtering only discards data but the capacity is still consumed.
- Even if your query only returns 2.5KB of data it will be rounded up and charged at the minimum 1 RCU of 4KB.
- Scan:
- Most flexible but least efficient operation for reading data in DynamoDB.
- It moves through the table item by item consuming the capacity of every item.
- You have complete control on what data is selected, any attributes can be used, any filter applied.
- It is far more expensive than query as it goes through every item - even though it is only returning a small selection.
Consistency Model:
DynamoDB can run in two modes - eventually consistent or strongly (immediately) consistent.
DDB is composed of a Leader Storage Node and Replicated Storage Nodes (across multiple AZs). When an attribute it updated through a write operation DDB directs the operation at the Leader Storage Node where the change first takes place -> Then the Leader Node replicates the data to the other Storage Nodes typically finishing in a few milliseconds.
It is possible for a read to occur during the replication of a write operation from the Leader Storage Node to the replications. Which is where consistency comes in, with an eventually consistent read DynamoDB will direct the operation to any Storage Node randomly meaning there is a small chance that read will occur on a node which has not yet had a change replicated to it.
If the read is a strongly consistent read then the read operation is always directed at the Leader Storage Node so the data returned is guaranteed to be up to date.
Eventually consistent reads scale a lot better and are actually cheaper - half the cost of strongly consistent. Remember that not all applications can use eventual consistency.
DynamoDB Operation & Performance SAA Exam Help:
- Capacity in DynamoDB refers to performance - not storage.
- 1 Read Capacity Unit is 1 x 4KB read operation per second.
- 1 Write Capacity Unit is 1 x 1KB write operation per second.
- Operations can't be less than 1 RCU or 1 WCU - they will be rounded up.
- If a read operation consumes 2KB of data it is rounded up to 1 RCU so 4KB.
- If a read operation consumes 6KB of data it is rounded up to 2 RCU so 8KB.
- Eventually consistent reads are half the cost of strongly consistent reads.
Dynamo DB Indexes
There are two types of DDB indexes Local Secondary Indexes (LSI) & Global Secondary Indexes (GSI). Indexes improve the efficiency or data retrieval operations in DynamoDB.
- Query is the most efficient operation in DDB but it is limited to only work on 1 PK value at a time and optionally a SK value.
- Indexes are alternative views on table data.
- You can create a view with a different SK (LSI) or different PK and SK (GSI).
- You can also choose which attributes to include.
LSI:
- An alternative view for a table
- Must be created with a table (can't be created after)
- Can have a maximum of 5 LSI's per table.
- Alternative SK to the base table.
- Shares the values assigned for RCU and WCU with the base table.
- Can have some or all of the attributes from the base table.
GSI:
- Can be created at any time.
- Limit of 20 per base table.
- Define a different PK and SK.
- Have their own RCU and WCU allocations (if the base table is using provisioned capacity).
- Can have some or all of the attributes from the base table.
- GSIs are always eventually consistent.
- Use GSIs as default - LSIs only when strong consistency is required.
DynamoDB Streams and Triggers
Streams:
- These are a time ordered list of Item changes in a table.
- 24 hour rolling window of these changes.
- Enabled on a per table basis.
- Records Inserts, Updated and Deletes.
Streams are the foundation for Database Triggers - these are serverless, event driven actions in Lambda based upon changes made to data in a DDB table. These are really useful for reporting and anayltics, data aggregation, messaging or notifications.
DynamoDB Global Tables
- This provides multi-master cross-region replication. There is no one master table.
- Tables are created in multiple regions and added to the same global table (becoming replica tables).
- Reads and Writes can occur in any region these changes are then replicated globally (generally in under a second).
- Can perform strongly consistent read operations, only in the same region as writes.
- Everything else is eventually consistent.
Amazon Athena
Amazon Athena is serverless querying service which allows for ad-hoc queries where billing is based on the amount of data consumed. You can take data stored in S3 and perform queries upon it.
- Data is never changed and remains on S3.
- When the data is read from S3 it is translated on the fly into a table like schema you define in advance. This allows Athena to read from it.
- This is called Schema-on-read.
- Again the data in S3 remains unchanged.
- Output of a query can be sent to other services.
- File formats Athena can read from include - XML, JSON, CSV/TSV, PARQUET and more.
- You can interact with data in S3 through SQL-Like queries - without transforming the source data.
ElastiCache
- ElastiCache is an in-memory database use for high performance workloads.
- It is not persistent so it is used for temporary data.
- Provides two different engines - Redis or Memcached (both as a service).
- This service is good for READ HEAVY workloads or low latency requirements.
- Reduces database workloads.
- Can be used to store User Session Data for servers (enables stateless servers).
- An application would need to know how to use ElastiCache it can't just be implemented with no application code changes.
Elasticache is very useful for scaling an application. When a user requests some data from the application -> the application will first check the cache for it -> If it does not exist the application will then read it from the DB -> the application then writes that data to the cache -> from now on if that data is requested it can be read from the cache.
Reading from the cache is a lot quicker and cheaper than from the DB. It means that the most popular data is kept cached and minimises DB read queries even as users grow. As if the number of users grows by a lot then the number of cache requests (cache hits) will grow a lot and the number of DB reads (cache misses) should only grow by a little.
ElastiCache SAA Exam Tips:
- An in-memory database for high performance workloads.
- Can use two different engines - Redis and Memcached.
- Memcached only supports simple data structures only (strings) & does not support replication or backups.
- Redis supports advanced data structures & data replication (Multi-AZ, HA) & backups / restore.
- Great for Ready Heavy workloads.
- Great for scaling to high read performance while minimising cost of reads.
- Can be used to store user session data enabling stateless servers.
Amazon Redshift
Redshift is a column based, petabyte scale, data warehousing product within AWS.
- Designed for reporting and analytics.
- It is OLAP (column based) not OLTP (row/transaction based).
- Pay as you use in a similar structure to RDS.
- Redshift Spectrum allows for direct querying large scale S3 data without first loading it in to Redshift.
- Federated Query allows for querying other Non-Redshift Databases.
- It is server based, not serverless.
- Not suitable for adhoc queries like Athena is as Redshift has a provisioning time.
- Runs in one AZ in a VPC - not HA by design.
- Redshift has an optional feature called Enhanced VPC Routing - traffic is routed according to VPC rules.
- Gives you advanced networking control.
Redshift Disaster Recovery and Resilience:
- By default Redshift is only in one AZ.
- Redshift can utilise S3 for backups.
- Can use automatic backups - which happen every 8 hours or 5gb of data added.
- Have a 1-day retention but this can be changed up to 35 days.
- Manual backups can be taken at any time and are only deleted when the user deletes them.
- S3 snapshots are automatically distributed across AZs.
- You can also configure snapshots to be copied to another AWS region.